转自公众号追一科技
阅读理解是近两年自然语言处理领域的热点之一,受到学术界和工业界的广泛关注。所谓机器阅读理解,是指让机器通过阅读文本,回答内容相关的问题,其中涉及到的理解、推理、摘要等复杂技术,对机器而言颇具挑战。
近日,追一科技语义算法研究员巨颖作为CMRC2018 中文机器阅读理解比赛的冠军团队成员之一,在雷锋网AI 研习社公开课上,为大家剖析机器阅读理解的关键知识点,并结合追一的实践经验,分享如何从数据、模型、训练角度提升模型性能,探讨AI 时代阅读理解技术的产品化落地。
分享嘉宾:
巨颖,追一科技语义算法研究员,清华大学硕士。主要负责阅读理解相关项目,为追一AIForce、坐席助手等产品提供技术支持,在阅读理解、文本分类、信息抽取等方面有深入的研究和丰富的应用经验。
以下为雷锋网AI 研习社整理分享内容
今天的分享主题是阅读理解进阶三部曲——关键知识、模型性能提升、产品化落地,分享提纲包括:
第一,介绍相关背景知识:常用数据集和基础架构;
第二,我们本次从CMRC2018 中文机器阅读理解比赛的获奖经验入手,介绍如何从数据、模型、训练等角度来阅读理解的模型性能;
第三,结合我在工作实践中的经验和体验来谈一谈阅读理解产品化落地的方向。
何谓阅读理解:常用数据集和基础架构
这部分主要介绍几个数据集和经典模模型。
数据集分为四个类别:
第一种是完形填空式;
第二种是多选式;
第三种是原文中的片段;
第四种是答案由人类总结而来。
每一种数据集我都会以一个案例来进行讲解:
完形填空式

多选式

原文中的片段

答案由人类总结而来

(关于四种数据集的案例讲解,请回看视频00:02 :45 处,
http://www.mooc.ai/open/course/596?=aitechtalkjuying)
接下来讲一些阅读理解的经典Model,主要包括:
Allen AI 提出的BIDAF
微软提出的R-NET
Google 提出的QANet
最近刷榜的GPT & BERT
进入Model 讲解之前,我们先思考一个问题:机器如何进行阅读理解?我们人类一般会先通读文章和问题,再带着问题重新阅读文章,并定位答案的区间,进而找到正确的结果,机器阅读也是一样:
第一步,将词汇向量化;
第二步:相当于阅读文章和阅读问题;
第三步:会采用Attention 的机制来实现,将文章和问题的信息进行融合。
现在进入到Model 介绍:
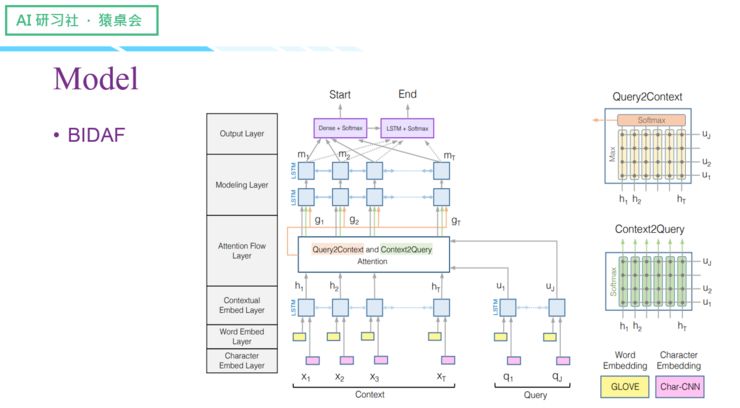
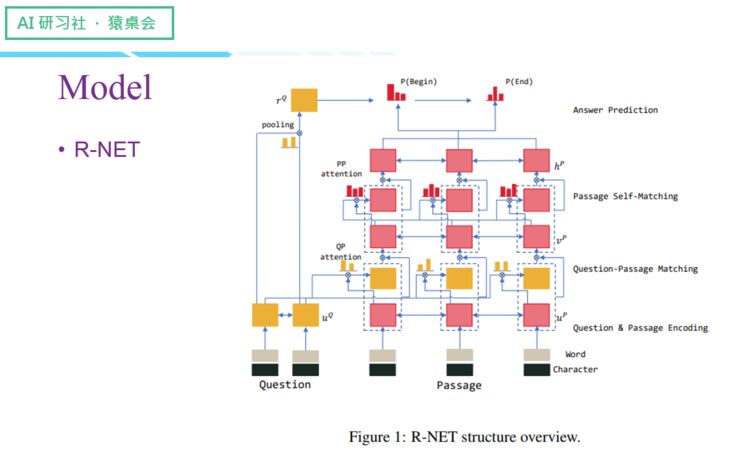
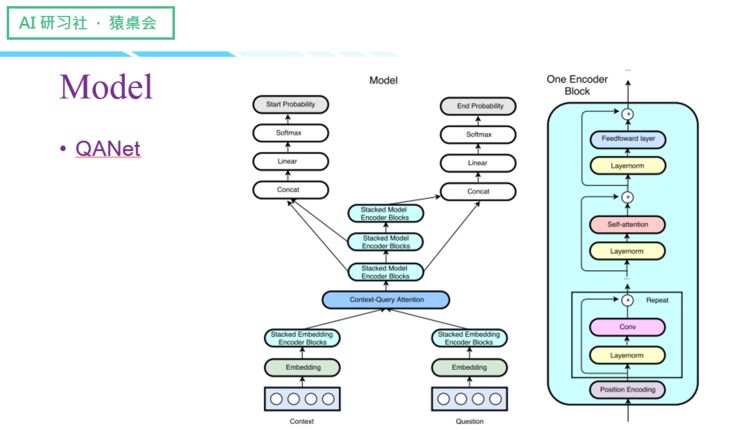
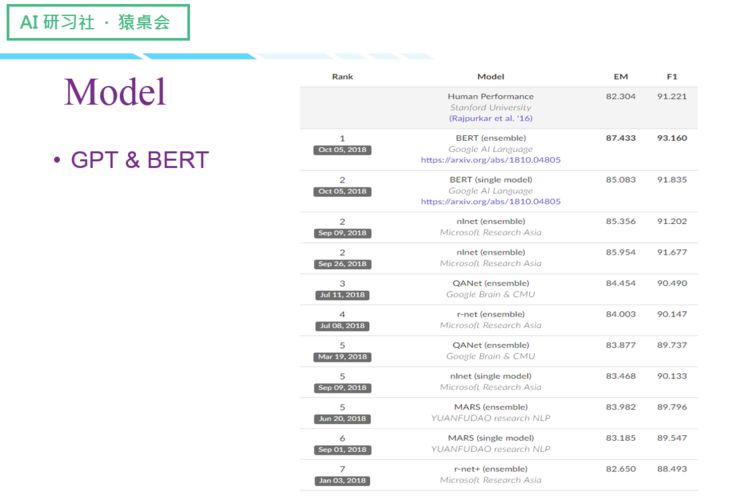
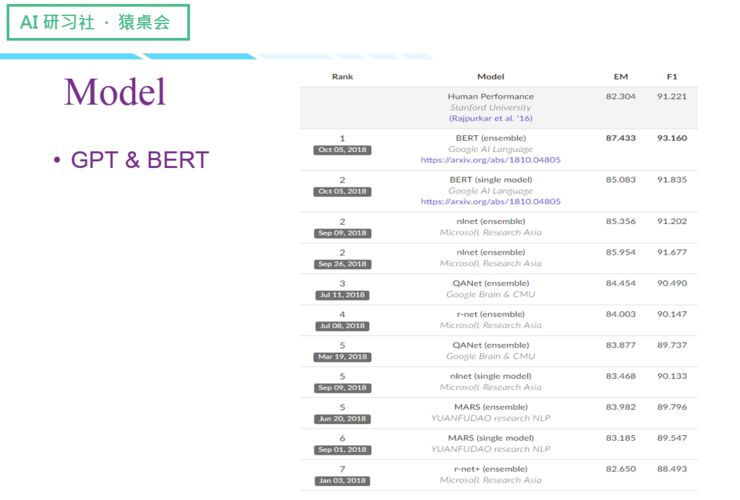
(关于这四个Model 的具体讲解,请回看视频00:13 :15 处,
http://www.mooc.ai/open/course/596?=aitechtalkjuying)
阅读理解的模型性能提升:从数据、模型、训练等角度
接下来我们从CMRC2018 中文机器阅读理解这个比赛入手,介绍我们如何从数据、模型、训练等角度来阅读理解的模型性能。
CMRC 由中国中文信息协会举办,中文全称为机器阅读理解大赛,它的整个数据构造都跟SQuAD 非常类似,只是换成了中文维基百科,它也是一个抽取式的阅读理解,一个问题对应一篇文章,问题数为1.9 万个,训练集大概是1 万条,验证集大概是3 千条,测试集大概是5 千条,答案一定是文章中的一部分,评测指标是EM & F1。
下面是CMRC 的一个例子:

(关于这一案例的具体讲解,请回看视频00:25 :10 处,
http://www.mooc.ai/open/course/596?=aitechtalkjuyinghttp://www.mooc.ai/open/course/596?=aitechtalkjuying)
首先是数据准备工作:



接下来介绍一下模型:
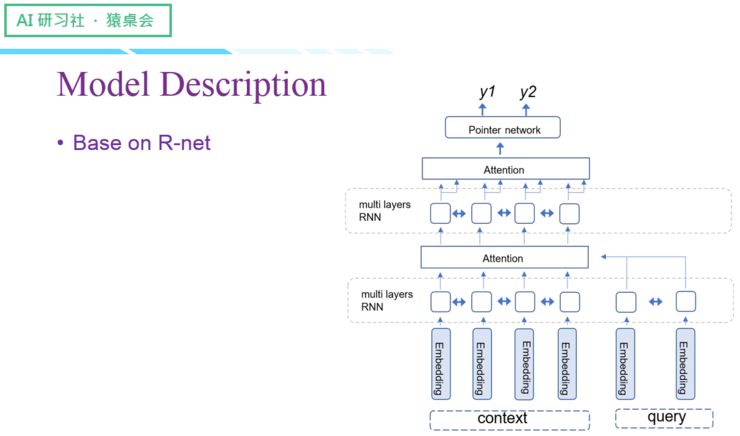

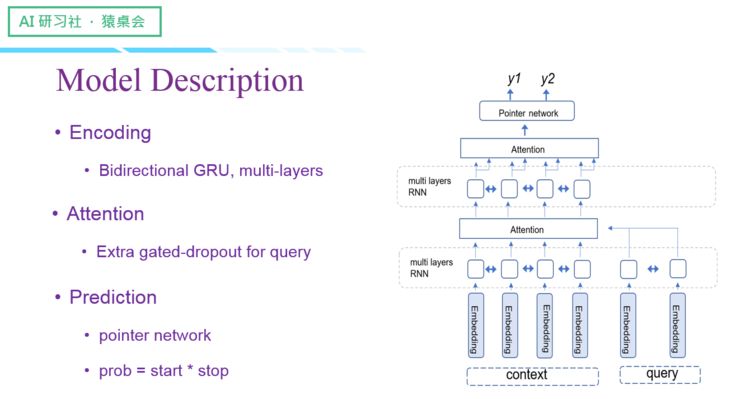
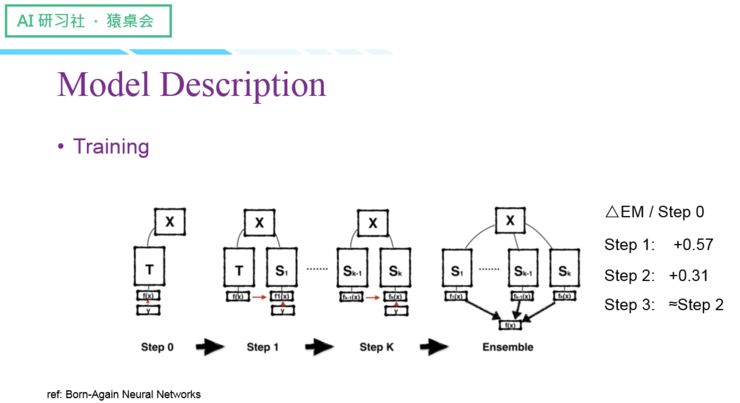
我们的实验结果如下:
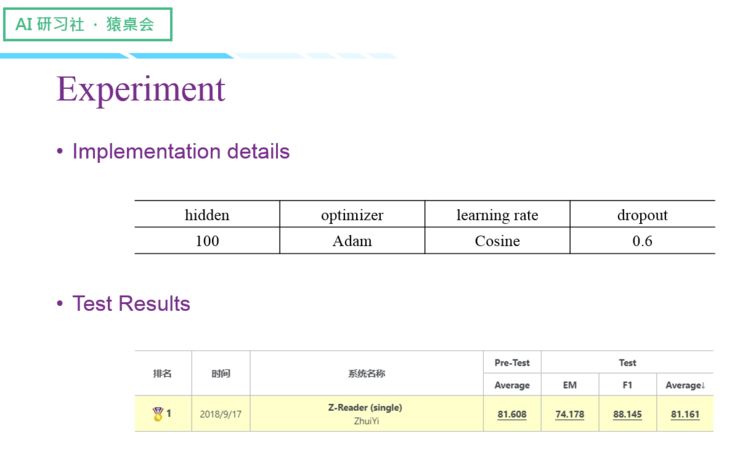
(关于CMRC 比赛的数据准备工作、模型以及实验结果的具体讲解,请回看视频00:25 :43 处,
http://www.mooc.ai/open/course/596?=aitechtalkjuying)
阅读理解的产品化落地
最后讲一讲阅读理解在实际产品中的应用。
首先最先想到的应用场景就是搜索引擎。搜索引擎一般都是基于网页的搜索,比如我现在输入一个问题,搜索引擎会返还给你一系列相关的网页,需要你点入网页找到答案位置,再提取出需要的信息,这都是跟人与人之间的问答交流不一样的。搜索引擎如何直接给用户返回最直接的答案,是各大产商都比较关心的一个问题。其中一个解决方案就是阅读理解。
(关于这部分的具体讲解,请回看视频00:37 :50 处,
http://www.mooc.ai/open/course/596?=aitechtalkjuying)
另外一个应用领域就是客服。以前如果需要机器回答用户的问题,需要人工提前阅读文档,对其中的知识点进行拆解,最后再交给机器处理,比较耗时耗力。有了阅读理解,机器就能直接阅读文章并进行回答,非常快捷。
其他还有金融、教育等领域,它们都存在大量非结构化文本。比如金融有很多公告类型的数据,纯靠人工提取知识点,并且由于长尾效应,难以覆盖到用户需要的所有点。依托阅读理解,机器可以直接从非结构化数据中提取到用户所需要的信息点。
实际应用中也存在不少的挑战:
一个挑战是专有领域的数据量比较少,解决方案有三个:一是翻译,二是用类似领域的数据来补充,此外最直接最可靠的就是人工标注,但是成本花费较大;
另一个挑战是实际应用中文档的复杂性。当数据集是文本时,文档可能长至几百页,这时,机器就需要搭配文章分类和段落索引这样的技术来提升速度和准确性。另外,文档中的一级标题、二级标题以及表格和图片等都是需要处理的问题。
最后讲一下我个人认为的阅读理解的发展方向:

一个是高层次的推理;
二是如何引用外部性、常识性的信息;
三是如何拒绝回答。
(关于阅读理解的三个发展方向的具体讲解,请回看视频00:43 :30 处,
http://www.mooc.ai/open/course/596?=aitechtalkjuying)
问答部分
1.teacher 的输出是训练集还是验证集?还有loss 是怎么算的,两个标签的loss 权重怎么设置?
teacher 的输出是训练集,实际上相当于我们先训练好了一个模型,我们把这个模型恢复进来,然后重新初始化一个student 模型,两者一起进行训练。就是说teacher 现在已经训练好了,然后来一个输入信息,teacher 的这个输出和student 原本真实的label 两者都作为监督信号去训练student。
loss 设计的时候可以把teacher 的输出当成另一个label。由真实的label 得到loss1,将teacher 的输出当成另一个label,采用相同计算方式得到loss2。在比赛中,二者的权重是一比一,即loss1+loss2
2. 训练的时候teacher 的变量用不用跟着student 一起更新?
实际上,我们在验证的时候一并尝试了这两种方式,一种是teacher 的变量跟着student 一起更新;另一种是teacher 的变量是固定的,只更新student 的变量。在CMRC 比赛中,这两种方式都有提升性能,但是teacher 的变量跟着student 一起更新时,提升的效果更好。
3. 有没有用过一个多任务的学习方式?
多任务的学习方式,一种是预测这个词是不是在答案的范围里面,输出 0,1 二分类的label 信号,将它当做辅助任务去训练,另外预测答案是否在这个句子里也可以是一个辅助任务。多任务其实是比较trick 的东西,不同任务设置的权重不一样,需要不断去尝试。
4.student 和teacher的predict 需要完整的训练集吗?
teacher 是跟着student的训练一起进行的,student 和teacher 的输入应该是全部训练集,一个bench 进来,先输入teacher。student 需要参考两个监督信号:一个是teacher 的输入,一个是真实的label。
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2018-12-5 9:48:08 |
2018-12-5 9:48:08 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}