转自公众号 数据派THU
简介
在我遇到的所有机器学习算法中,KNN是最容易学会的。尽管它很简单,但事实证明它在某些任务中非常有效(我们将在本文中看到)。
甚至于在某种情况下它是更好的选择,毕竟它可以同时用于分类和回归问题!不过,它更常用来解决分类问题,很少看到在回归任务中使用KNN。提起KNN可以被用于回归任务,只是想说明和强调一下当目标变量是自然连续的时候,KNN也会同样有效。
在本文中,我们将首先理解KNN算法背后的直观解释,看看计算点之间距离的不同方法,然后在Big Mart Sales数据集上用Python实现KNN算法。让我们开始吧!
目录
1. 一个简单的例子来理解KNN背后的直观解释
2. KNN算法是如何工作的?
3. 点之间距离的计算方法
4. 如何选择k因子?
5. 应用在一个数据集上
6. 额外的资源
1. 一个简单的例子来理解KNN背后的直观解释
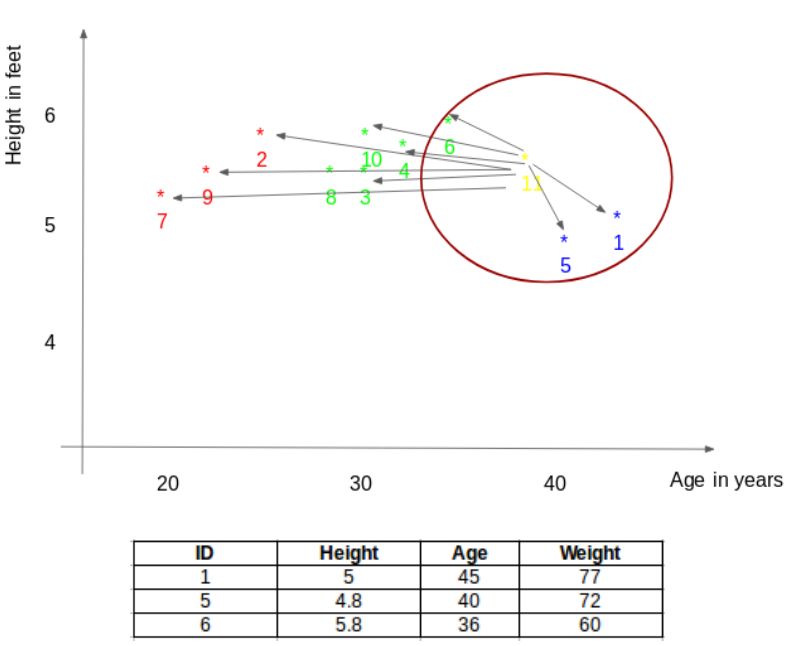
让我们从一个简单的例子开始。考虑下表——它包括10个人的身高、年龄和体重(目标)。如图所示,ID11的体重值丢失了。下面,我们需要根据这个人的身高和年龄来预测他的体重。
注意:该表中的数据不代表实际值。它只是作为一个例子来解释这个概念
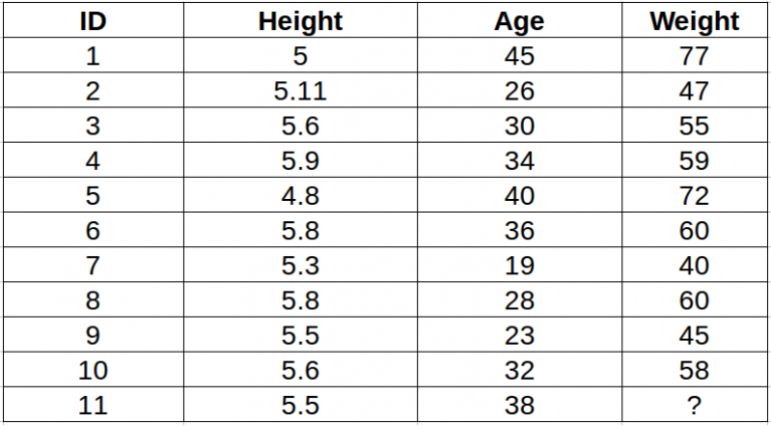
为了更清楚地了解这一点,下面是从上表得出的身高与年龄的关系图:
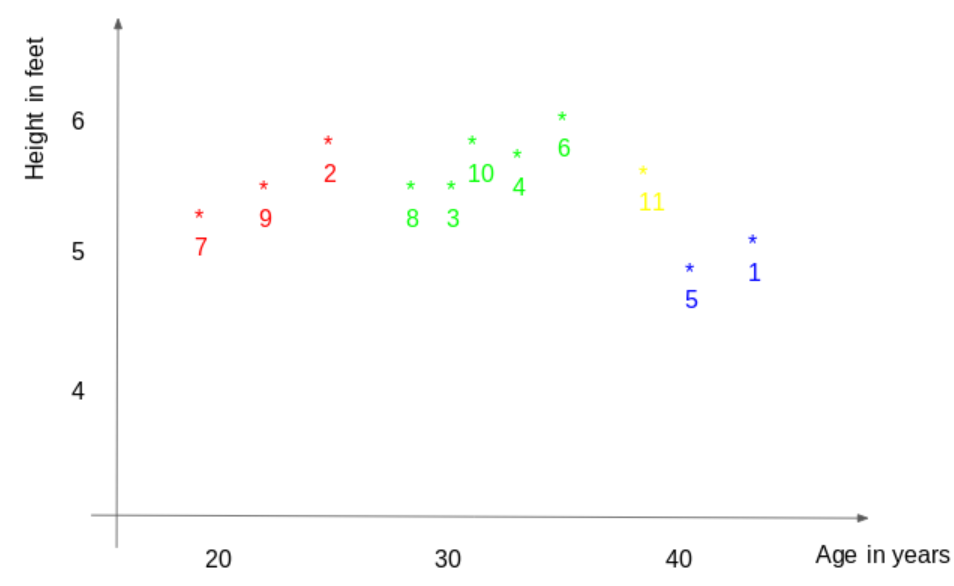
在上图中,y轴代表一个人的身高(以英尺为单位),x轴代表年龄(以年为单位)。这些点是根据ID值编号的。黄色点(ID 11)是我们的测试点。
如果让你根据上图来确定编号ID11这个人的体重,你的答案会是什么?你可能会说,因为ID11更接近于点5和点1,所以这个人的体重应该与这些id相似,可能在72-77公斤之间(表中ID1和ID5的体重)。这是有道理的,但是算法是如何预测这些值的呢?我们会在这篇文章里找到答案。
2. KNN算法是如何工作的?
如上所述,KNN可以用于分类和回归问题。该算法使用“特征相似度”来预测任何新数据点的值。这意味着,根据与训练集中点的相似程度为新点赋值。从我们的示例中,我们知道ID11的高度和年龄与ID1和ID5相似,所以重量也大致相同。
如果这是一个分类问题,我们会把众数作为最终的预测。在本例中,我们有两个体重值——72和77。谁能猜到最终值是如何计算的?我们会将两个取值的平均值作为最终的预测结果。
下面是这个算法的具体步骤:
首先,计算新点与训练集中每一个点的距离。
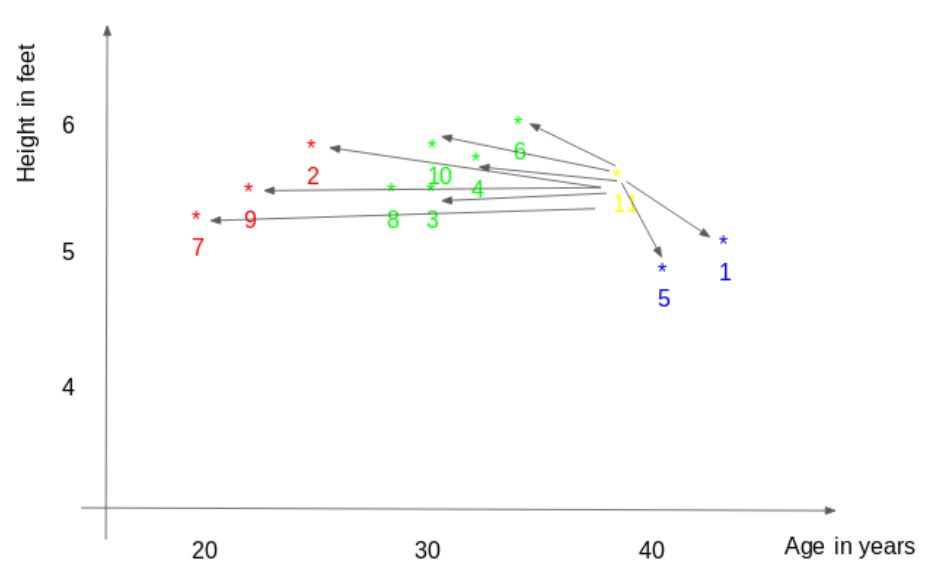
选出与新点最接近的K个点(根据距离)。在这个例子中,如果K=3,点1,5,6将会被选择。在本文后续部分,我们会进一步探索选择正确K值的方法。
将所有点的均值作为新点的最终预测值。在这个例子中,我们可以得到ID11的体重=(77+72+60)/3 = 69.66kg。
接下来的几个小节里,我们将讨论以上三个步骤的具体细节。
3. 点之间距离的计算方法
第一步是计算新点与训练集中每个点之间的距离。计算这个距离的方法有很多种,其中最常见的方法是欧几里得法、曼哈顿法(连续的)和汉明距离法(离散的)。
欧几里得距离:欧几里得距离是新点(x)和现有点(y)之间的平方差之和的平方根。
曼哈顿距离:这是实向量之间的距离,用它们差的绝对值之和来计算。

汉明距离:用于离散变量,如果(x)和(y)值相等,距离D就等于0。否则D = 1。
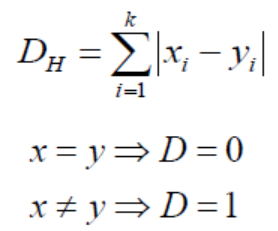
一旦计算完成新观测点与训练集中点之间的距离,下一步就是挑选最近的点。点的数量由K值决定。
4. 如何选择k因子?
第二步是确定K值。在为新观测点赋值时,K值决定了需要参考的邻点数量。
在我们的例子里,对于K=3,最近的点就是ID1、ID5和ID6。
ID11的预测体重是:
ID11 = (77+72+60)/3
ID11 = 69.66 kg
对于k=5,最近的点是ID1、ID4、ID5、ID6和ID10。
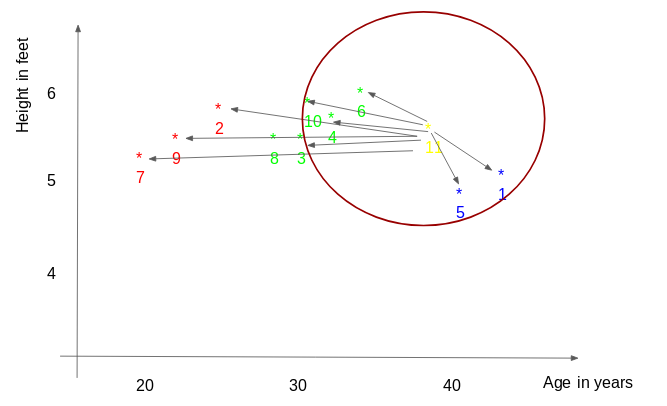
ID11的预测体重是:
ID 11 = (77+59+72+60+58)/5
ID 11 = 65.2 kg
我们注意到,基于k值,最终结果往往会改变。那么如何求出k的最优值呢?让我们根据训练集和验证集的误差计算来决定(毕竟,最小化误差是我们的最终目标!)
请看下面的图表,不同k值的训练错误和验证错误。
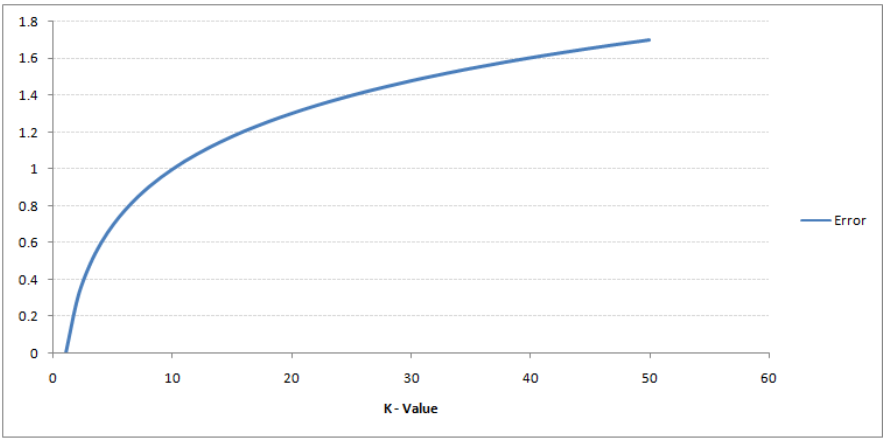
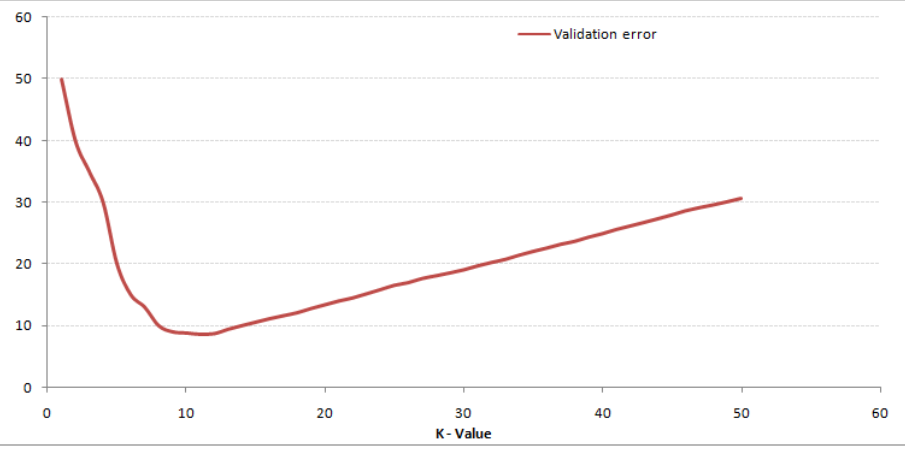
K值很低时(假设k = 1),该模型过拟合训练数据,从而导致验证集的错误率很高。另一方面,k取较大值时,模型在训练集和验证集上表现都很差。如果你仔细观察,验证误差曲线的值在k = 9时达到最小值,此时k值是模型的最优值(根据不同的数据集会有所不同)。这条曲线被称为“手肘曲线”(因为它的形状很像手肘),通常用于确定k值。
我们还可以使用网格搜索技术来确定k值。在下一个小节里我们将会介绍它。
5. 应用在一个数据集上
读到现在,你应当对算法有一个清晰的理解。如果你还有问题,请给我们的公众号留言,我们很乐意回答。现在,我们将在数据集中实现该算法。我已经使用了Big Mart sales数据集来展示算法实现的过程,大家可以从这个链接下载它。
读取文件
import pandas as pd
df = pd.read_csv('train.csv')
df.head()
计算缺失值
df.isnull().sum()
#missing values in Item_weight and Outlet_size needs to be imputed
mean = df['Item_Weight'].mean() #imputing item_weight with mean
df['Item_Weight'].fillna(mean, inplace =True)
mode = df['Outlet_Size'].mode() #imputing outlet size with mode
df['Outlet_Size'].fillna(mode[0], inplace =True)
处理分类变量,删除id列
df.drop(['Item_Identifier', 'Outlet_Identifier'], axis=1, inplace=True)
df = pd.get_dummies(df)
创建训练和测试集
from sklearn.model_selection import train_test_split
train , test = train_test_split(df, test_size = 0.3)
x_train = train.drop('Item_Outlet_Sales', axis=1)
y_train = train['Item_Outlet_Sales']
x_test = test.drop('Item_Outlet_Sales', axis = 1)
y_test = test['Item_Outlet_Sales']
预处理——扩展特征
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
x_train_scaled = scaler.fit_transform(x_train)
x_train = pd.DataFrame(x_train_scaled)
x_test_scaled = scaler.fit_transform(x_test)
x_test = pd.DataFrame(x_test_scaled)
看看不同K值的错误率
#import required packages
from sklearn import neighbors
from sklearn.metrics import mean_squared_error
from math import sqrt
import matplotlib.pyplot as plt
%matplotlib inline
rmse_val = [] #to store rmse values for different k
for K in range(20):
K = K+1
model = neighbors.KNeighborsRegressor(n_neighbors = K)
model.fit(x_train, y_train) #fit the model
pred=model.predict(x_test) #make prediction on test set
error = sqrt(mean_squared_error(y_test,pred)) #calculate rmse
rmse_val.append(error) #store rmse values
print('RMSE value for k= ' , K , 'is:', error)
输出:
RMSE value for k = 1 is: 1579.8352322344945
RMSE value for k = 2 is: 1362.7748806138618
RMSE value for k = 3 is: 1278.868577489459
RMSE value for k = 4 is: 1249.338516122638
RMSE value for k = 5 is: 1235.4514224035129
RMSE value for k = 6 is: 1233.2711649472913
RMSE value for k = 7 is: 1219.0633086651026
RMSE value for k = 8 is: 1222.244674933665
RMSE value for k = 9 is: 1219.5895059285074
RMSE value for k = 10 is: 1225.106137547365
RMSE value for k = 11 is: 1229.540283771085
RMSE value for k = 12 is: 1239.1504407152086
RMSE value for k = 13 is: 1242.3726040709887
RMSE value for k = 14 is: 1251.505810196545
RMSE value for k = 15 is: 1253.190119191363
RMSE value for k = 16 is: 1258.802262564038
RMSE value for k = 17 is: 1260.884931441893
RMSE value for k = 18 is: 1265.5133661294733
RMSE value for k = 19 is: 1269.619416217394
RMSE value for k = 20 is: 1272.10881411344
#plotting the rmse values against k values
curve = pd.DataFrame(rmse_val) #elbow curve
curve.plot()
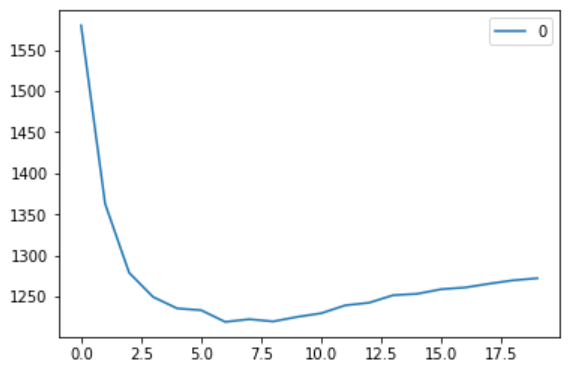
正如我们所讨论的,当k=1时,我们得到一个非常高的RMSE值。RMSE值随着k值的增加而减小。在k= 7时,RMSE约为1219.06,并进一步增加k值。我们可以有把握地说,在k=7这种情况下,会得到最好的结果。
这些是使用训练数据集得到的预测结果。现在让我们预测测试数据集的值并提交。
在测试集上得到预测值
#reading test and submission files
test = pd.read_csv('test.csv')
submission = pd.read_csv('SampleSubmission.csv')
submission['Item_Identifier'] = test['Item_Identifier']
submission['Outlet_Identifier'] = test['Outlet_Identifier']
#preprocessing test dataset
test.drop(['Item_Identifier', 'Outlet_Identifier'], axis=1, inplace=True)
test['Item_Weight'].fillna(mean, inplace =True)
test = pd.get_dummies(test)
test_scaled = scaler.fit_transform(test)
test = pd.DataFrame(test_scaled)
#predicting on the test set and creating submission file
predict = model.predict(test)
submission['Item_Outlet_Sales'] = predict
submission.to_csv('submit_file.csv',index=False)
提交这个文件,我得到了一个RMSE 1279.5159651297。
实现网格搜索(Gridsearch)
为了确定k值,每次绘制手肘曲线是一个繁琐的过程。我们可以简单地使用gridsearch来找到最佳值。
from sklearn.model_selection import GridSearchCV
params = {'n_neighbors':[2,3,4,5,6,7,8,9]}
knn = neighbors.KNeighborsRegressor(
model = GridSearchCV(knn, params, cv=5)
model.fit(x_train,y_train)
model.best_params输出:
{'n_neighbors': 7}
6. 额外的资源
在本文中,我们介绍了KNN算法的工作原理及其在Python中的实现。这是最基本也是最有效的机器学习技术之一。对于在R中实现KNN,您可以浏览这篇文章:使用R的KNN算法。
在本文中,我们直接使用sklearn库中的KNN模型。您还可以从头实现KNN(我建议这样做!),这篇文章将对此进行介绍:KNN simplified。
如果你认为你很了解KNN,并且对该技术有扎实的掌握,在这个MCQ小测验中测试你的技能:关于KNN算法的30个问题。祝你好运!
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2018-11-29 11:42:07 |
2018-11-29 11:42:07 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}