转自公众号机器学习与大数据挖掘
开始陆续介绍决策树与随机森林,理解原理与会用来做分类算法是其一,更重要的是要理解决策树构造的精髓并加以推广应用才是算融会贯通。
先来看看所谓的树结构,其实很简单,就是从一个节点往下依次不断分裂节点的一种结构,比如下面这个图描述的是根据一个人的信息(包括职业、年龄、收入、学历)去判断他是否有贷款的意向的树结构图:
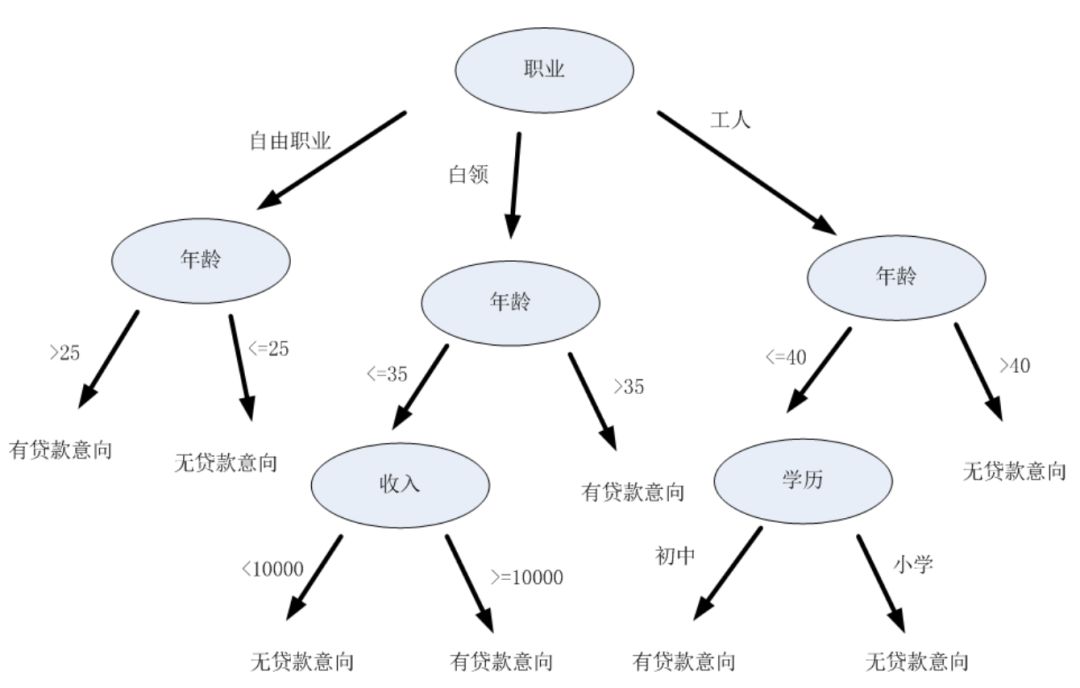
可以看到,所谓的树结构其实就是一大堆有顺序的if-else条件判断语句的组合,如果职业是什么,走向对应分支,再如果年龄是什么,走向一条分支,一直到没有分支了为止。而我们的决策树就是想建立这样的一个组合条件的树结构,树的最底层给出分类的结果,这样给定一组(职业、年龄、收入、学历)的特征,在这个树结构中过一遍就能得到结果了。有一个宏观的认识我们再来细说决策树的构造过程。
第一步,从我们拥有的数据说起。
上面的树结构是最终的结果,而最开始我们并不知道这个结构, 大多数时候我们所拥有的只是训练样本,也就是特征以及标签,比如下面这样:
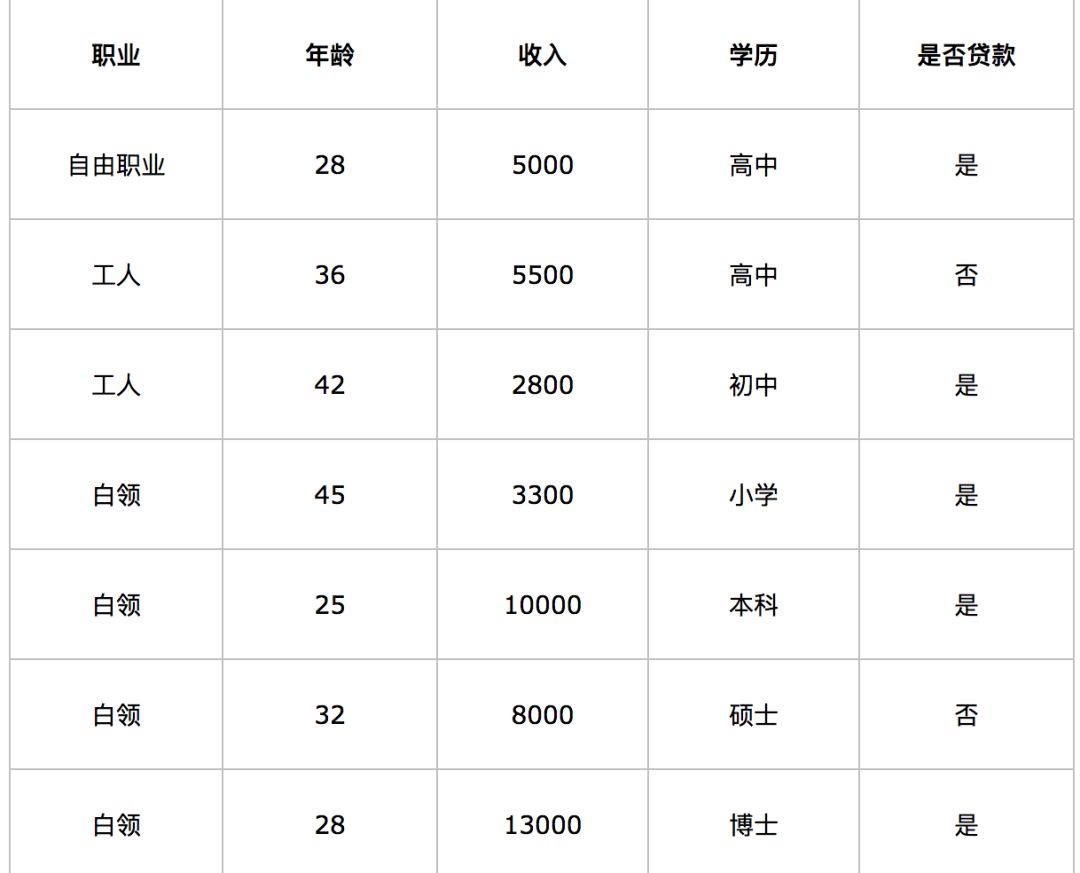
在实际情况中,所有的属性都可以数值化表示,比如职业属性的这一栏,可以用1,2,3,4代表不同的职业(工人,白领等),依次类推,非数值化属性的数值化表示是一个非常常见的操作。
第二步,如何选择根部属性节点。
也许你已经注意到,上面的决策树根节点是职业,为什么是职业不是年龄也不是收入?不是因为它们不可以当根节点,而是有一套算法指导选择“职业”这一属性时是最优选择,这也是决策树构造中最为核心的步骤与思想:属性选择。那么究竟如何选择不同属性的?
首先我们需要有一个非常重要的认识:如何评判一个属性的好坏,很简单,就是这一维度的属性和分类标签的相关程度到底大不大。比如说上面这个例子,假如我们单看“收入”属性,如果说恰好收入>5000的对应的标签全是1,收入<=5000的标签全是0,那么我们可以说收入是一个非常好用且适合的维度特征,甚至可以不需要其他属性,单靠“收入”就可以做到完美的分类了。而实际情况下通常不是这样,单一的“收入”属性不管怎么划分,都无法实现完全的分类。同理,单一的“职业”属性,“年龄”属性等属性都无法做到这个事。这个时候我们只能在这几个属性里面找一个尽可能好的属性。那么怎么数学化的定义这个好呢?数学上一种方法就是信息熵。
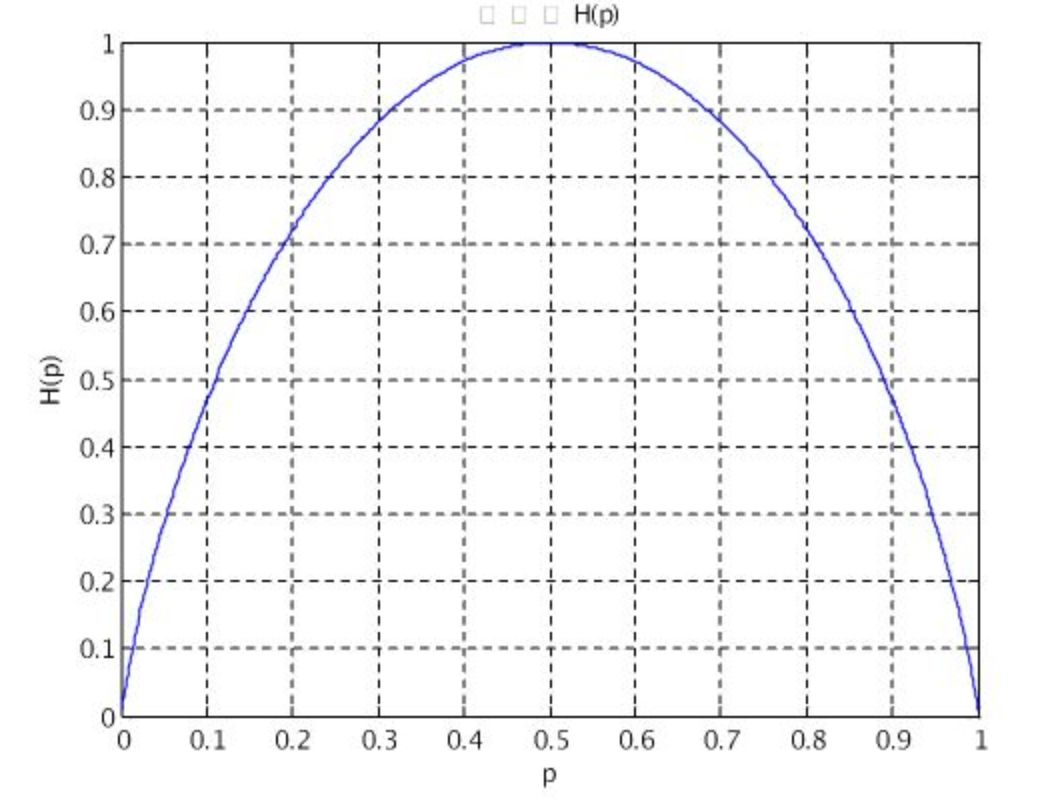
先来看一下熵,所谓熵简单理解就是代表着信息量的多少,描述的就是一个系统的混乱程度,不确定度。举个例子,假如我们用p表示明天会不会下雨的概率,那么什么情况下不确定度最大呢?当然是p=0.5的时候,这个时候就是可能下雨也可能不下,概率是一样的,假如p=0,那就是不下雨,非常确定,可以理解为没什么混乱,太确定了。假如p=1,那就是下雨,也非常确定,也没有什么混乱。这两种情况因为太确定了就没什么信息量。用一个数学公式来表示这个确定与不确定的大小就是:H = -p * log(p) 。我们画出p在0-1之间变化的时候H的值的变化关系图如图所示:
这是一个变量,假如一件事情发不发生和很多变量有关,每个变量都有一个p,那么整体的信息量就可以表示:
H(X)=−∑p(xi)log(p(xi)) (i=1,2,…,n)
有了这样一个不确定度的衡量标准,我们再来看看决策树里面如何根据这个东西来选择属性的。这里选择的标准就是选择某个属性对结果混乱程度的影响大小来决定。
首先我们来看一下谁都不选,系统的混乱程度是多少,也就是信息熵是多少,怎么计算呢?以上述例子中的贷款作为标签,假设能贷款是标签1,不能是0,那么上面的表里面有5个1,2个0,这样1的概率是p(1) = 5/7,而0的概率是p(0) = 2/7,这样可以计算出一个基于标签的信息熵:h = -5/7 * log(-5/7) - 2/7 * log(2/7) = 0.863
其次我们来看一下假如选了“收入=5000”作为分割节点,那么想评价一下这么分割的好坏,就可以先计算一下按照这么分以后系统的信息熵(不确定度)是多少,然后和原来的比一下看不确定度下降了多少,假如降的多那么就可以说“收入=5000”作为分割点比较好。
具体什么意思呢?举个极端的例子(只是举例子,不是上表的实际情况),假设“收入=5000”非常好,恰好可以把上面标签0和1完全分开,这样按照“收入>5000”分到的子集合1就是(1,1,1,1,1),而“收入<5000”分到的子集2就是(0,0),这个时候我们再去计算子集合1的信息熵h1,发现里面p(1)=5/5=1,p(0) = 0/5=0,信息熵h1=0;而对于子集合2的信息熵,p(1)=0/2=0,p(0) = 2/2=0,信息熵h2=0,按此条件划分下的整个信息熵h'=h1+h2=0。那么可以看到,“收入=5000”的划分可以使得系统的信息熵降为0,相比之前降低了(h-h')=0.863。
重新整理一下,其实上面的h'在数学上定义就是一种条件熵,也就是给定条件下的信息熵,对应到上面也就是“收入=5000”分割条件下的系统信息熵。而(h-h')就可以表示为信息增益,数学表示就是ent_prap = H(Y) - H(Y|X),为什么叫信息增益而不是信息减益呢?直观的理解,就是这一维特征能给系统带来多大的信息,带来的信息越多越重要,可能最开始是从带来信息量大小角度来考虑的,所以叫增,其实减的多的反面不就是增的多吗。
上面说的“收入=5000”恰好可分比较极端,即使不恰好可能,也能同理计算出一个条件熵吧,只是不为0,同理也能计算一个信息增益。
这是我们以“收入”作为分割属性,那么以“职业”、“学历”等任何一个维度进行分割是不是也能得到各自的信息增益呢,没错,所以决策树在第一层选择特征的时候是会遍历所有的特征维度的,然后选择信息增益最大的那一维作为分裂属性。
一旦第一层节点找到划分的维度以后,就可以得到划分后的结果,而每一种划分结果有可以重复上述划分的过程,不同的是第二层的划分属性里面已经没有第一层的属性维度了,也就是属性维度减1,一直这样下去最终就可以建立起文章开头我们看到的那个决策树了。
决策树的构造思路大概就是这样,当然具体的实现细节还有很多需要探讨的。比如:
(1)上述我们以“收入=5000”作为分割,那么你怎么知道是5000这个分割点呢?
(2)“收入=5000”进行分割可以分割成两半,大于5000的一条路,小于等于5000的一条路,这也只是两条路,为什么非要是两条路呢,咋不是3条路?4条路?比如“收入<5000”,“8000<收入<5000”,“10000<收入<8000”,“收入>10000”,那么具体几条路怎么规定也是需要探讨的。
(3)再有分裂节点不可能一直往下分吧,也就是树的深度需要合理的控制,树的深度可能直接影响模型的拟合程度,也是需要考虑的。
(4)再有,属性选择只有信息熵一种方法吗?其实不是,信息熵是最早出来并使用的,比较经典,其实还有基尼系数等,但是它们都有一个共性,那就是曲线符合上面给的一个图,当p=0.5的时候不确定度最大。等等。
上面的探讨,后面会再介绍。
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2018-12-7 10:32:02 |
2018-12-7 10:32:02 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}