本文转自公众号智能运维平台
简介
本文将向大家介绍一篇来自数据挖掘顶会KDD 2018,Research track的论文,Feedback-Guided Anomaly Discovery via Online Optimization。这篇文章基于主动学习的思想,提出了基于反馈的异常检测框架(以下简称Feedback-guided Anomaly Detection),将领域知识成功的融入到异常检测算法中。针对异常检测模型输出的异常分数排名,运维人员对排名靠前的样本给出反馈(正常或者异常),不断地根据每一次的反馈结果迭代优化异常检测模型,从而减少模型的误报率和漏报率。
背景
异常检测在网络入侵检测,维护系统稳定性和服务可靠性方面有重要作用。通用的异常检测器一般都是识别统计意义上的离群点(outlier),然后根据输出的异常分数给出一个排名,排名越靠前的样本越有可能是异常,但是统计意义上的离群和真实业务场景下的异常是有区别的,这就会导致目前的异常检测器有很高的误报率。一种有效减少误报率的方法就是把运维人员的领域知识(domain knowledge)融合到检测器中。
标注异常是一种暴力的融入领域知识的方法,通过标注出来的异常和正常,将异常检测问题转换成分类问题。但是标注数据是一直个很棘手的问题,1)需要有业务背景的专业人员;2)时间成本高;3)需要标注的数据量太大。因此,大多数的互联网公司和运维人员都不愿意去标注数据。在机器学习领域中,主动学习(active learning)的目的就是利用尽可能少的标注数据,使模型的性能达到最优。
在这篇文章中,基于主动学习(active learning)的思想,作者提出了一种运维人员参与的交互异常检测框架。根据运维人员对异常检测结果提供的反馈,异常检测模型迭代更新,从而减少误报率。在传统的异常检测中,算法会输出异常分数的排名供运维人员参考,运维人员会按照异常分数从高到低的顺序一一核查,如果运维人员感兴趣的业务异常被排在后面(如图1所示,红色的点为异常),那么就会花费很高的时间成本来找到它们。
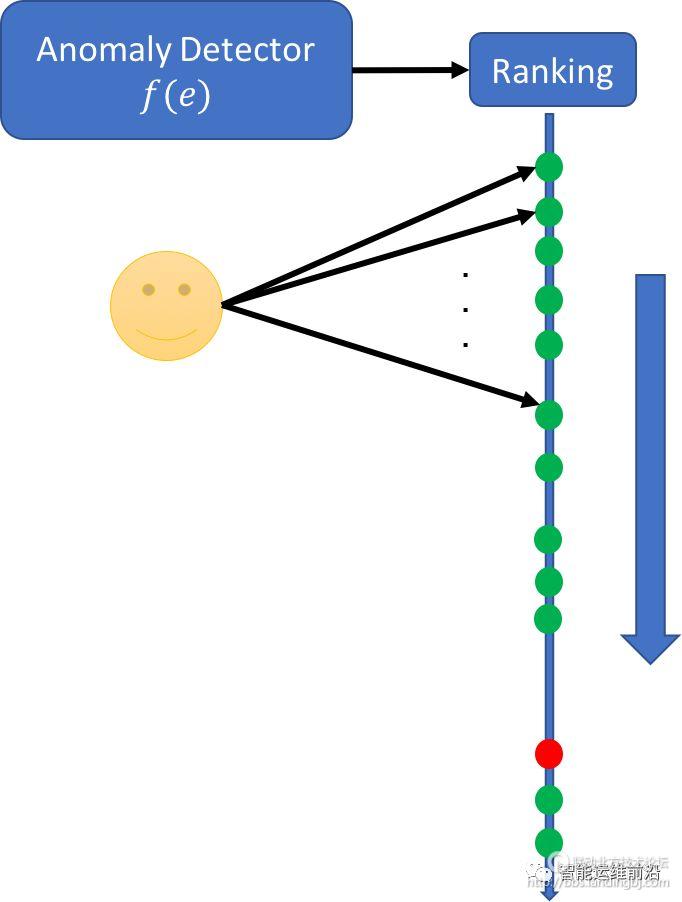
图1 运维人员核查异常示意图
为了节约排查时间,在这篇论文中,运维人员会把自己的领域知识融入到异常检测中,针对初始的异常分数排名,给出排名靠前的样本的反馈之后,模型会根据这个反馈来重新调整参数,从而输出新的异常分数排名,目的是使运维人员感兴趣的异常排在靠前的位置,从而节约排查异常所需的时间。此外,文章把反馈引导的异常检测问题转换成了在线凸优化的算法框架,并且对运维人员的反馈定义一个凸损失函数,推导出了简单、高效、有效的优化算法。 通过把这套框架应用到孤立森林(Isolation Forest),在公开数据集的实验和一个大规模空间安全安全应用的实例证明了框架的有效性。
问题描述
对于m 个样本集合D ,由正常样本集N 和异常样本集A 组成,一般来说,正常样本的个数远多于异常样本的个数。因为D 的样本量是非常大的,所以手工搜索异常是不现实的。异常检测器为每一个样本计算一个异常分数,目的是让异常样本排在正常样本前面,但是没有一个异常检测器是完美的,经常会有正常样本排在前面的情况。在后面的实验中,我们用两个评价指标,一个是每次反馈后有多少异常样本被发现,另一个是发现第一个异常样本需要人工核查多长时间。
系统框架
1. 在线凸优化
根据运维人员的反馈来调整异常检测器的参数可以转换成在线凸优化(onlineconvex optimization)的问题。首先给定异常检测器(论文中假设异常检测器都是广义线性模型)的一组参数wt ,和一个凸损失函数ft, 计算在wt下损失ft(wt),优化的目标是让Regrett接近0,其中w*是检测器的最优参数配置。
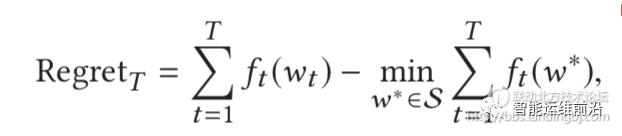
2.损失函数
首先定义yt =1代表异常,yt =-1表示正常。显然,如果得到的top-rank 反馈是yt =1,也就是说异常样本被排在最前面,说明目前的模型是好的,损失函数的值需要减少;反之,如果得到的反馈是yt =-1,说明正常点排在前面,那么这个模型是有问题的,需要增大损失函数。
•线性损失(linear loss)
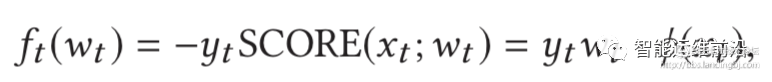
线性损失是关于wt的线性函数,显然也是凸函数。Score 是归一化之后的,显然,如果反馈的yt =1,那么ft(wt) <0,损失函数的值会减少,反之,yt =-1,那么yt(wt) >0,损失函数的值会增加,和前面我们的期望是一致的。
• 对数似然损失(log-likelihood loss)
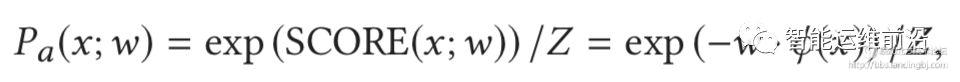
其中Z是归一化常数:
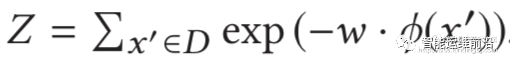
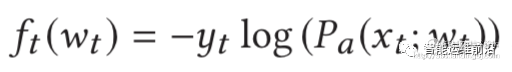
•逻辑斯蒂损失(logistic loss)
和线性损失类似,但是实验证明没有线性损失好,所以没有在论文里详细说明。
3. 镜像下降学习算法
通过前面两个步骤,定义好了损失函数和优化目标,现在需要使用优化算法求得最优解。文章采用的是基于梯度下降的镜像学习算法,细节见图2所示。

图2 镜像下降优化算法
应用
把上述的框架应用到孤立森林(Isolation Forest)。在IForest 中,根节点到叶子节点的路径长度反映样本的异常程度,路径越短,越可能是异常。基于此我们可以定义参数w和特征向量q(x),用we 表示边e (或者节点)的权重,qe(x)表示从根节点到叶子节点是否经过了这条边(节点),那么异常分数可以表示为SCORE(x;w)=-w *q(x)。当某个样本对应的叶子节点距离根节点比较远,那么路径会经过较多的边,显然SCORE会比较小(负号),这与IForest 的初衷是一致的。在实验初始化阶段,所有的边的权重都等于1。Isolation Forest 的迭代反馈流程如图3所示。
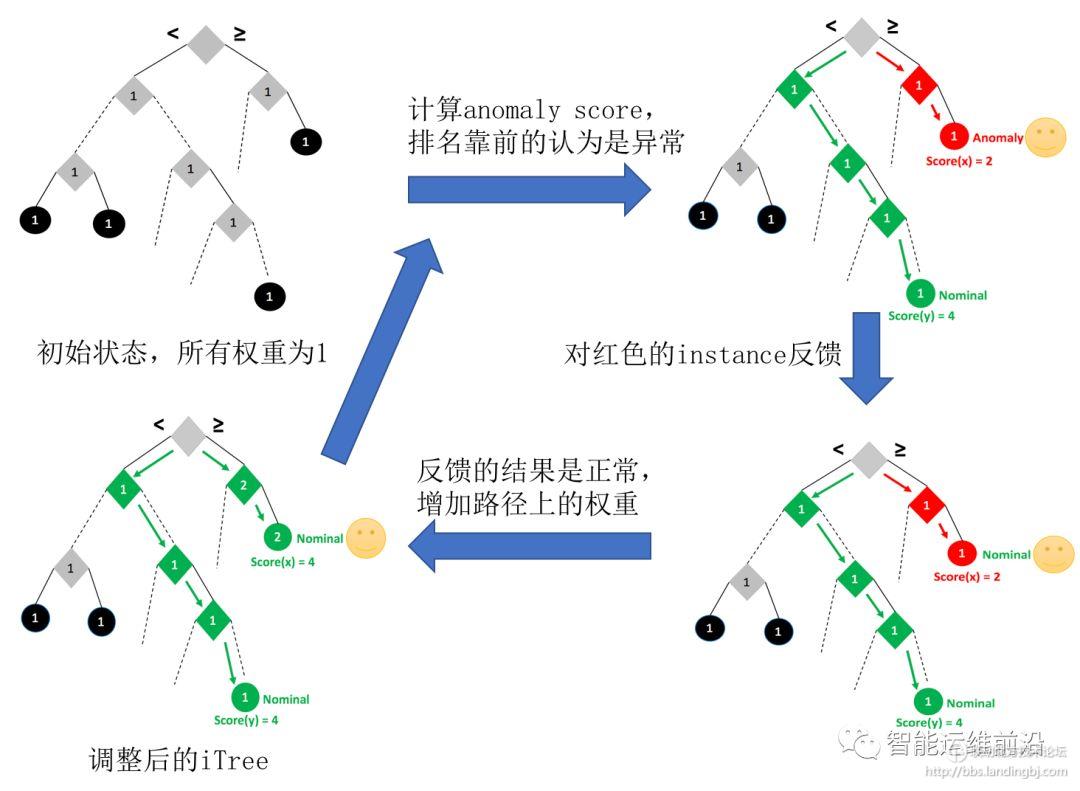
图3 Isolation Forest 迭代反馈示意图
实验
实验主要分为两个部分,一个是在公开数据集上的实验,考虑到异常检测的公开数据集很少,这里采用的是分类数据集,将其中的占比很小的类别作为异常样本;另一个是在实际应用中空间安全中的入侵检测数据集,异常样本就是恶意攻击的实体。
在公开数据集上的实验结果如图4所示,横坐标是反馈迭代的次数k,纵坐标是top-k中发现的异常个数,显然,Feedback-guided Anomaly Detection(log-likelihood, linear)能够发现更多的异常。
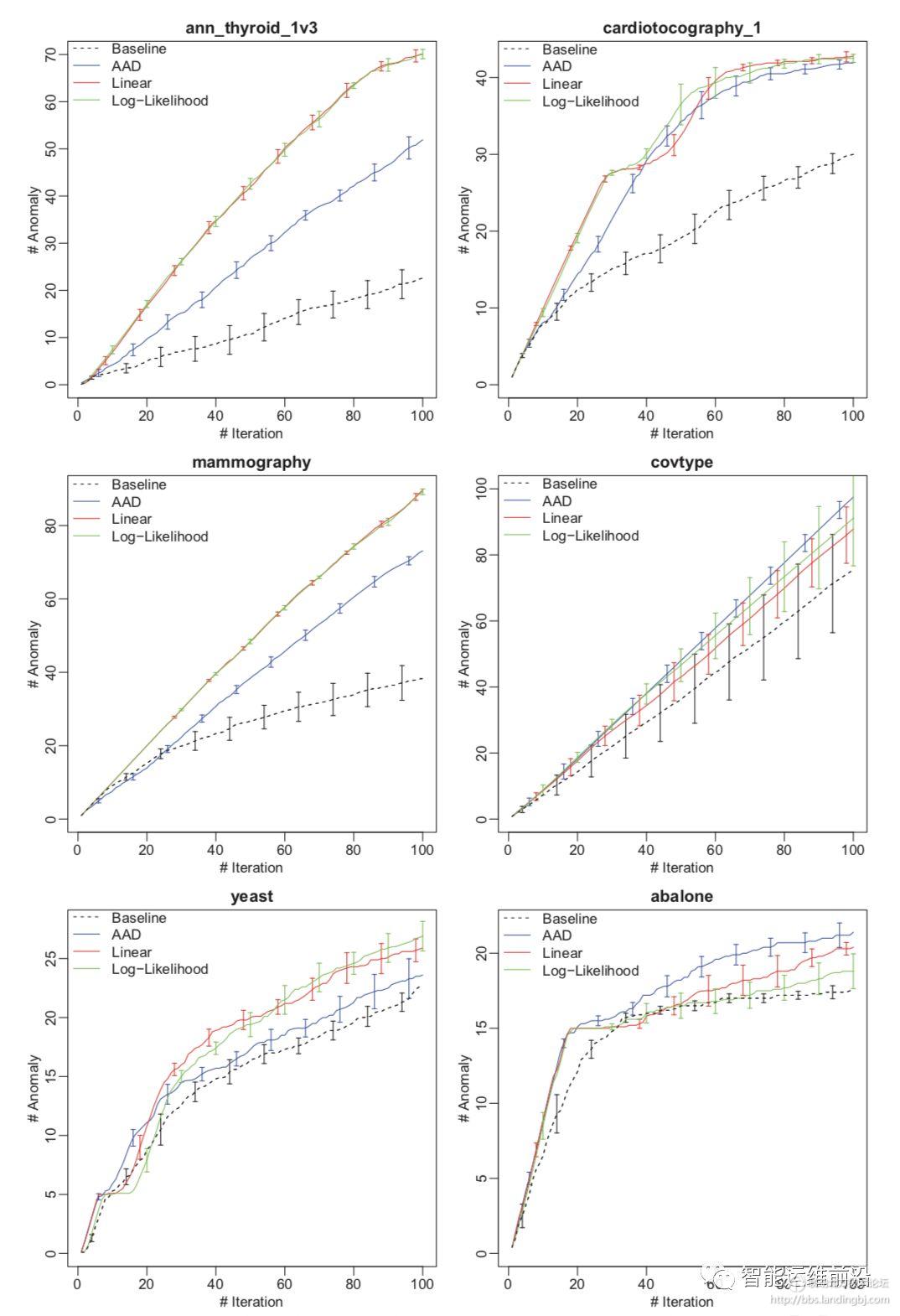
图4 公开数据集中发现的异常数量对比
在空间安全的实际应用中的结果如图5所示,可以看出Feedback-guided Anomaly Detection 可以发现更多的异常攻击样本。此外,实验还统计了发现第一个恶意攻击样本所需要的时间,如图6所示,显然,Feedback-guided Anomaly Detection 可以更早的发现第一次恶意攻击的样本,这对空间安全、入侵检测等有重要意义。
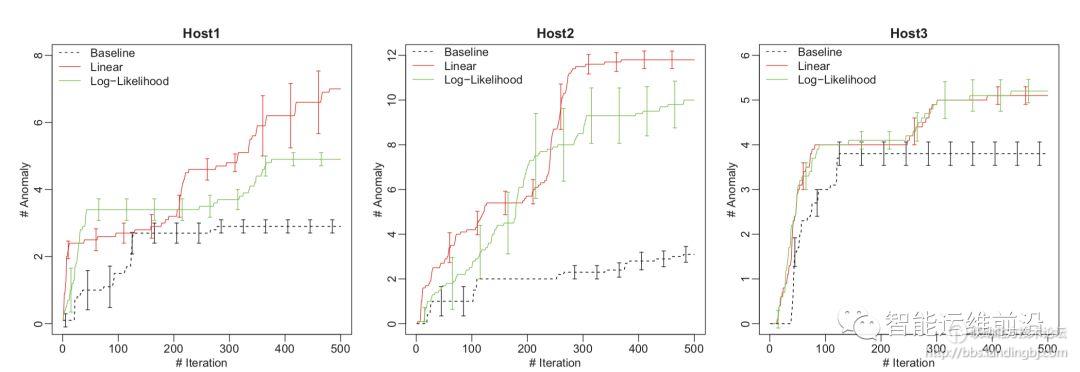
图5 攻击数据集中发现的异常数量对比
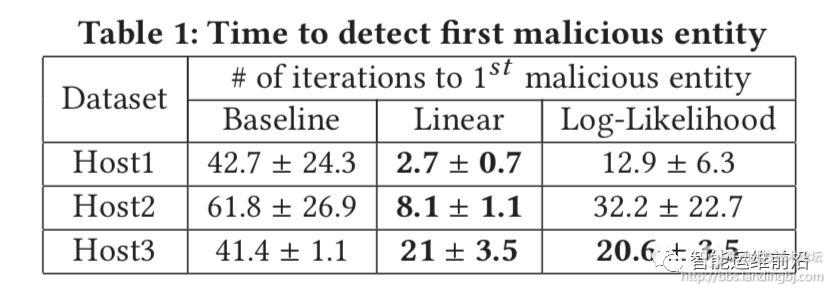
图6 发现第一个恶意实体(异常)需要的时间
此外,实验部分还分析了镜像下降算法中学习率(learning rate)对实验结果的影响,以及反馈样本是正常还是异常对实验结果的影响,由于篇幅限制,就不在这里详细介绍,有兴趣的可以参考原文。
结论
这篇文章基于主动学习的思想,提出了一个人工交互、迭代优化的异常检测系统。运维人员可以向无监督异常检测的结果提供反馈,从而优化异常检测模型,减少误报率。文章通过在线凸优化和定义两种损失函数解决了迭代优化问题。通过在大规模公开数据集上的实验结果证明,与没有反馈的基线算法和之前论文提出的Active Anomaly Detection (AAD) 算法相比,Feedback-guided Anomaly Detection显著提高了异常检测的效果。此外,实际应用到大规模空间安全数据集上,论文的方法能够较早的发现恶意攻击,并且可以发现可以找到更多的异常。
关于未来工作,论文中对于异常检测器的假设前提是可以表示成广义线性模型,可以尝试将文中的框架应用到任意的异常检测器中。此外,开发一个交互界面有助于对实验结果做出解释,并且更好的理解业务异常和统计异常。
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2018-12-10 10:39:11 |
2018-12-10 10:39:11 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}