作为软件工程师,不可避免地受到周围计算机工具的影响,语言、框架、甚至执行过程都会影响我们构建的软件。
数据库亦如此,基于一种特殊的方式,不可避免地影响到我们对应用程序中易变和共享状态的处理。
过去的十多年,我们采用不同的方式去探寻这个世界。采用不同理念的一小众开源项目,它们不断成长,你中有我,我中有你。平台集成了这些工具,每个控件通常都能提高某些基础硬件或者系统效能。结果是平台无法通过任何单一的工具解决某些问题,不是太过笨重,就是局限于某一特定部分。
因此当今数据平台多种多样,从简单的缓存层、多语言持久化层到整个集成数据管道,针对多种特定需求的多种解决方案。在某些方面,确实有不错的表现。
因此本对话的目的就是解释一些流行的方式方法如何发挥作用,为什么会有如此表现。我们先来考虑组成它们的基本元素,这样便于在后续的讨论中对这些认识通盘地考虑。
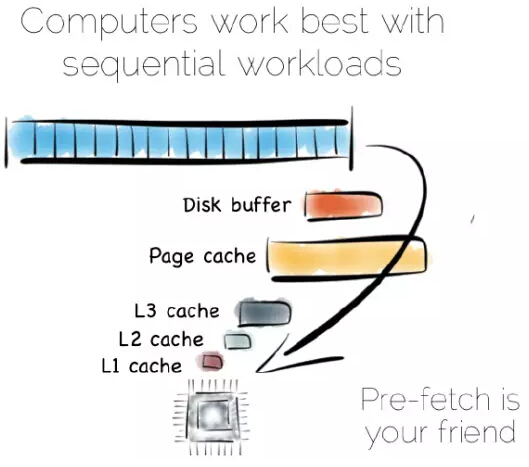
从某种抽象的角度看,当我们处理数据时,实际上就是对其进行局部性(locality)处理,局部性到CPU、局部性到我们需要的其它数据。有序地获取数据是其中很重要的部分,计算机很擅长序列化的操作,这些操作是可以预测的。
若是有序地从硬盘中获取数据,数据会预获取存入硬盘缓存、页缓存、以及不同层级的CPU缓存中,这可以极大地提升性能。但这对随机数据寻址意义不大,这些数据存于主内存、硬盘或者网络中。实际上,预获取反倒会拉低随机负载能力:不论是各种缓存或是前端总线,充满了不太会被用到的数据。

硬盘通常被认为性能稍低,而主内存稍快些。这种认识不见得一直是对的,随机和有序主内存负载之间相差一两个数量级。用某种语言管理内存,事情往往会变得更加糟糕。
从硬盘有序获取的数据流性能确实好过随机寻址主内存,或许硬盘并不像我们想的那样跟乌龟似的,至少在有序获取的情况不会很慢。固态盘(SSD),特别是采用PCIe接口,正如它们显示不同的权衡,将事情复杂化。但采用这两种获取模式带来的缓存收益是不变的。
译者注:数据流就是大量连续到达的、潜在无限的有序数据序列,这些数据按顺序存取并被读取一次或有限次。
假设我们要创建一个简单的数据库,首先从基础部分文件开始。
保持有序读和写,文件在硬件上会表现地很好。我们可以将写入的数据放入文件的末尾,可以通过扫面整个文件进行数据读取。任何我们希望的处理过程可以随着数据流穿过CPU而成真,比如过滤,聚合、甚至做一些更复杂的操作,总之非常完美。
倘如数据发生诸如更新这样的变化会怎样?
我们有多个选择,在某个位置更新这个值。我们需要利用固定长度的字段,在我们浅显的思想实验中这是没有问题的。不过在某个位置更新数据意味着随机输入输出流(IO),这会影响性能。
替代的办法是将更新值放置在文件的末尾,在读取值时对过期的数据进行处理。
我们第一次做出权衡,将“日记”或者“日志”放在文件末尾,就能保证有序获取进而提高性能。另外倘若某处需要更新数据,可以实现每秒300次左右的读取,前提是更新数据刷入底层介质中。
实际上完整的读取文件是很慢的,获取十亿字节(GB)数据,最好的硬盘也需要花费数秒,这是一个数据库全表扫描所花费的时间。
我们时常只需要一些特定的数据,比如名为“bob”的客户,这时扫描整个文件就不妥当,我们需要一个索引。
我们可用许多不同类型的索引,最简单的一种是固定长度的有序数组,比如本例中的客户名,和对应的偏移量一起存放在一个堆文件中。有序数组可以进行二进制搜索查找。同样,我们可以用树结构、位图索引、哈希索引、字典索引等。这里是一个树的结构图。
索引就像是在数据中添加了一个总览结构,值是有序排放的,这样我们就能快速获取我们想要读取的数据。但总览结构有个问题,数据进来时需要随机写。因此理想的、写优化仅仅追加文件;考虑到写会打散文件系统,这会使一切变慢。
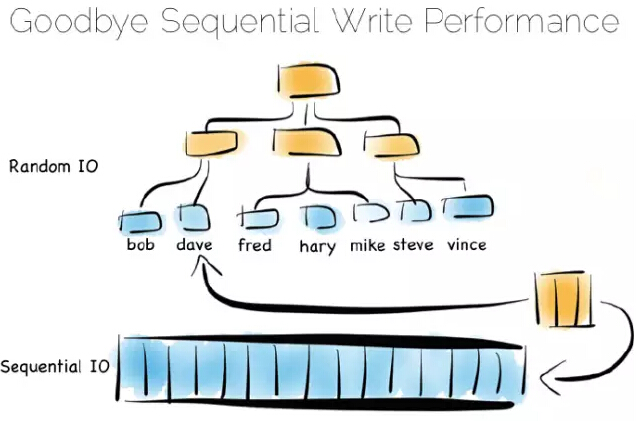
如果你将许多索引放入一个数据库表中,那你一定熟悉这个问题。假定我们使用的机械盘,用这种方式维护某个索引的硬盘完整性,速度大约慢1000倍。
幸运的是,这里有几种解决方案。这里我们讨论三种,它们都是一些极端地例子。在现实世界中,远没有这么复杂,但在考虑海量存储时这些概念会特别有用。
第一种方案是将索引放入主内存,随机写问题分隔到随机存储存储器(RAM),堆文件依旧在硬盘中。
这是一种简单但行之有效的方案,可以解决我们随机写的问题。这种方式在许多数据库中已得到应用,比如MongoDB、Cassandra、Riak、以及其他采用此优化类型的数据库,它们常常用到内存映射文件。
一种流行的方式抛开单个的“总览”索引,转而采用相对较小的索引集合。
这是一个简单的理念:数据进来,我们批量地将其写入主内存。一旦内存数据足够多,比如达到MB,我们就对它们进行排序,而后将它们作为单个小的索引写入硬盘中。最后得到的是一个小的、由不变索引文件组成的年表。
那么这样做的好处是?这些不变的文件集合被有序地流化处理,这样就能快速地写,最重要的是无需将整个索引加载入内存中。真棒!
当然它也有一个缺点,当读操作时需要询问非常多的小索引。我们将随机IO(RandomIO)写问题变为读问题。不过这确实一个很好的权衡策略,而且随机读比随机写更容易优化。
实际开发中,偶尔也需要清理孤子更新,但它有序读和写确实不错。
我们创建的这个结构称作日志结构合并树(Log Structured Merge Tree),这种存储方式在大数据工具中应用较大,如HBase、Cassandra、谷歌的BigTable等,它能用相对较小的内存开销平衡写、读性能。
将索引存储在内存中,或者利用诸如日志结构合并树(Log Structured Merge Tree)这样的写优化索引结构,绕开“随机写惩罚”(random-write penalty)。这是第三种方案为纯粹的简单匹配算法(Pure brute force)。
回到开始的文件例子,完整地读取它。如何处理文件中的数据,可以有许多选择。简单匹配算法(brute force)通过列而非行来存储数据,这种方法叫做面向列。
需要注意的是真实的列存储及其遵循的大表模式(Big Table pattern)之间存在一种不好的命名术语冲突。尽管它们有一些相似的地方,事实上它们是不同的,所以将它们视为不同的事情是一件明智的。
面向列是一种简单的理念,和行存储数据不同,通过列分割每一行,将数据追加到单个文件末尾。接着在每个单独的文件中存储每一列,一旦需要只需读取需要的列。
这样可以确保文件的含有相同的序列,即每个列文件的第N行含有相同的地址或者偏移量。这个很重要,在某一时刻读取多列,来服务一个单一的查询。意味着“连接(joining)”列速度飞快,倘若所有的列含有相同的序列,我们就能在一个紧凑的循环中这么做,此循环有很好缓存和CPU利用率。许多实现大量使用向量( vectorisation)进一步优化简单连接和过滤操作吞吐量。
写操作可以提高只在文件末尾追加( being append-only)性能。不利的地方是很多文件需要更新时,文件的每个列需要单独写入数据库。最常见的解决方案是采用类似日志结构合并(LSM)方式,进行批量化的写操作。许多列类型的数据库通过给表添加一个完整的序列来提升读的性能。
需要记住几件事,一是schema,二是时间、分布式、异步系统风险。但这些问题都是可控的,前提是你认真对待。未来大数据领域可能会出现这样一些新的工具、革新,逐渐掺入到平台中,解决过去和现在更多的问题。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-8-4 10:52:50 |
2015-8-4 10:52:50 |
 赞(
赞( 操作
操作

 不明觉厉!!!
不明觉厉!!!{kind=link}
{kind=link}