转自公众号追一科技
Google AI最近又掀起了瓜界旋风。这次是BERT模型刷爆了阅读理解的各项测试,一夜间大家似乎走进了NLP的"新时代"。
在11项NLP任务中,BERT模型夺得SOTA结果,在自然语言处理学界以及工业界都引起了不小的热议,瓜界也是惊呼变天了。那天晚上10点,当我带着澎湃的心情,跑上13楼求教我司实力与颜值兼具的算法大拿锋哥的时候,锋哥还神游在密密麻麻的代码世界里。过了半晌,才悠悠地回了一句,“你们啊,太不关心我们研发了。”
锋哥说BERT模型“吃下”了33亿文本的语料数据,堪称大块头,然后又在不同的下游任务中“微调”,就像骆驼穿过针眼一样,很精细,最终在不同任务中取得了目前最好的效果。
“远在天边,近在眼前,不知道我们今年就在搞这个东西吗?每天就知道在前端APP、微信上跟机器人撩来撩去,底层算法关心有木有?BERT也绝非平地惊雷,模型也是有兄弟姐妹,高矮胖瘦的好伐。”明天我给你码一篇,好好解读下BERT的来龙去脉。
BERT的“前任”们
早在2015年的时候,微软研究院的何凯明和他的同事们发表了残差网络的论文,第一次通过残差的方式将卷积神经网络推进到了100层以上,并在图像识别的任务上刷新了当时的最高纪录。
自那以后起,随着网络不断地加深,效果也在不断提升。然而大量的数据训练出来的大型网络虽然效果更好,但随着网络的加深以及数据集的不断扩大,完全重新训练一个模型所需要的成本也在不断地增加。
因此在计算机视觉处理中,人们越来越多地采用预训练好的大型网络来提取特征,然后再进行后续任务。目前这种处理方式已经是图像处理中很常见的做法了。
相比之下,自然语言处理目前通常会使用预训练的词向量来进行后续任务。但词向量是通过浅层网络进行无监督训练,虽然在词的级别上有着不错的特性,但却缺少对连续文本的内在联系和语言结构的表达能力。
因此大家也希望能像图像领域那样,通过大量数据来预训练一个大型的神经网络,然后用它来对文本提取特征去做后续的任务,以期望能得到更好的效果。其实这一方向的研究一直在持续,直到今年的早些时候AllenAI提出的ELMo由于其在后续任务上的优异表现获得了不小的关注。
在CMRC2018阅读理解比赛中,追一科技的参赛方案就运用了ELMo模型的预训练方式,并做了相应的改进,并拿下了测试的第一名。因为原本的ELMo当中对英文进行了字符级别的编码,但这对中文并不适用。我们在此基础上改进为笔画级别的编码,同时结合原有的词级别编码一起通过双层LSTM变换来进行语言模型预训练。经过实验验证,最后选择了512维的词级别ELMo向量进行后续任务。
在ELMo获得成功以后不久FastAI就推出了ULMFiT,其大体思路是在微调时对每一层设置不同的学习率。此后OpenAI又提出了GPT。追一科技在文本蕴含、观点型阅读理解等任务中,就采用了GPT模型作为预训练方案。预训练的语言模型是在百度15亿词文本的语料上进行的,模型参数选择了12层,12head的Transformer结构。然后采用此模型直接在子任务上微调来进行后续任务。
从上面提及的这些论文的结果以及学界和工业界的反馈来看,这种使用大量的语料进行预训练,然后再在预训练好的模型上进行后续任务训练,虽然训练方式各有不同,但在后续任务都有不同程度的提高。
而谷歌提出的BERT就是在OpenAI的GPT的基础上对预训练的目标进行了修改,并用更大的模型以及更多的数据去进行预训练,从而得到了目前为止最好的效果。
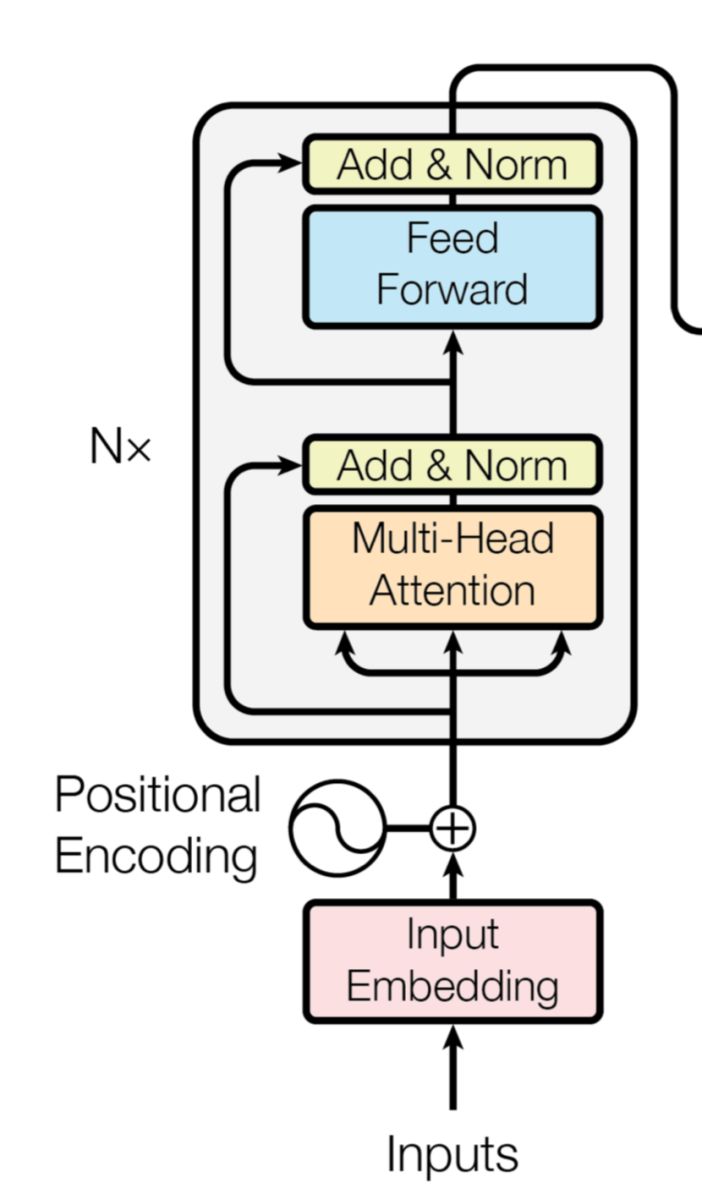

Trransformer的编码器结构
BERT主体结构和创新点
BERT模型沿袭了GPT模型的结构,采用Transfomer的编码器作为主体模型结构。Transformer舍弃了RNN的循环式网络结构,完全基于注意力机制来对一段文本进行建模。
Transformer所使用的注意力机制的核心思想是去计算一句话中的每个词对于这句话中所有词的相互关系,然后认为这些词与词之间的相互关系在一定程度上反应了这句话中不同词之间的关联性以及重要程度。因此再利用这些相互关系来调整每个词的重要性(权重)就可以获得每个词新的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。
Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。

Transformer的注意力层得到的词-词之间关系
GPT则利用了Transformer的结构来进行单向语言模型的训练。所谓的语言模型其实是自然语言处理中的一种基础任务,其目标是给定一个序列文本,预测下一个位置上会出现的词。
模型学习这样的任务过程和我们人学习一门语言的过程有些类似。我们学习语言的时候会不断地练习怎么选用合适的词来造句,对于模型来说也这样。例如:
> 今天 天气 不错, 我们 去 公园 玩 吧。
这句话,单向语言模型在学习的时候是从左向右进行学习的,先给模型看到“今天 天气”两个词,然后告诉模型下一个要填的词是“不错”。然而单向语言模型有一个欠缺,就是模型学习的时候总是按照句子的一个方向去学的,因此模型学习每个词的时候只看到了上文,并没有看到下文。
更加合理的方式应该是让模型同时通过上下文去学习,这个过程有点类似于完形填空题。例如:
>今天 天气{ }, 我们 去 公园 玩 吧。
通过这样的学习,模型能够更好地把握“不错”这个词所出现的上下文语境。
而BERT对GPT的第一个改进就是引入了双向的语言模型任务。
此前其实也有一些研究在语言模型这个任务上使用了双向的方法,例如在ELMo中是通过双向的两层RNN结构对两个方向进行建模,但两个方向的loss计算相互独立。追一科技在文本意图模型中,也加入了通过上下文预测某个词的辅助任务,通过实验发现在做意图分类的同时加入这个辅助任务能够让编码器尽可能的包含输入文本的全局信息,从而提高意图判断的准确率。
而BERT的作者指出这种两个方向相互独立或只有单层的双向编码可能没有发挥最好的效果,我们可能不仅需要双向编码,还应该要加深网络的层数。但加深双向编码网络却会引入一个问题,导致模型最终可以间接地“窥探”到需要预测的词。这个“窥探”的过程可以用下面的图来表示:

从图中可以看到经过两层的双向操作,每个位置上的输出就已经带有了原本这个位置上的词的信息了。这样的“窥探”会导致模型预测词的任务变得失去意义,因为模型已经看到每个位置上是什么词了。
为了解决这个问题,我们可以从预训练的目标入手。我们想要的其实是让模型学会某个词适合出现在怎样的上下文语境当中;反过来说,如果给定了某个上下文语境,我们希望模型能够知道这个地方适合填入怎样的词。
从这一点出发,其实我们可以直接去掉这个词,只让模型看上下文,然后来预测这个词。但这样做会丢掉这个词在文本中的位置信息,那么还有一种方式是在这个词的位置上随机地输入某一个词,但如果每次都随机输入可能会让模型难以收敛。
BERT的作者提出了采用MaskLM的方式来训练语言模型。
通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号来代替它们。尽管模型最终还是会看到所有位置上的输入信息,但由于需要预测的词已经被特殊符号代替,所以模型无法事先知道这些位置上是什么词,这样就可以让模型根据所给的标签去学习这些地方该填的词了。
然而这里还有一个问题,就是我们在预训练过程中所使用的这个特殊符号,在后续的任务中是不会出现的。
因此,为了和后续任务保持一致,作者按一定的比例在需要预测的词位置上输入原词或者输入某个随机的词。当然,由于一次输入的文本序列中只有部分的词被用来进行训练,因此BERT在效率上会低于普通的语言模型,作者也指出BERT的收敛需要更多的训练步数。
BERT另外一个创新是在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务。这个任务的目标也很简单,就是预测输入BERT的两端文本是否为连续的文本,作者指出引入这个任务可以更好地让模型学到连续的文本片段之间的关系。在训练的时候,输入模型的第二个片段会以50%的概率从全部文本中随机选取,剩下50%的概率选取第一个片段的后续的文本。
模型大小和数据量都很重要
以上的描述涵盖了BERT在模型结构和训练目标上的主要创新点,而BERT的成功还有一个很大的原因来自于模型的体量以及训练的数据量。
BERT训练数据采用了英文的开源语料BooksCropus以及英文维基百科数据,一共有33亿个词。同时BERT模型的标准版本有1亿的参数量,与GPT持平,而BERT的大号版本有3亿多参数量,这应该是目前自然语言处理中最大的预训练模型了。
当然,这么大的模型和这么多的数据,训练的代价也是不菲的。谷歌用了16个自己的TPU集群(一共64块TPU)来训练大号版本的BERT,一共花了4天的时间。对于是否可以复现预训练,作者在Reddit上有一个大致的回复,指出OpenAI当时训练GPT用了将近1个月的时间,而如果用同等的硬件条件来训练BERT估计需要1年的时间。不过他们会将已经训练好的模型和代码开源,方便大家训练好的模型上进行后续任务。
虽然训练的代价很大,但是这个研究还是带来了一些思考和启发。例如双向语言模型的运用,多任务对预训练的帮助以及模型深度带来的收益。相信在未来的一段时间,自然语言处理中预训练的神经网络语言模型会得到更多的关注和运用。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2018-10-18 17:26:32 |
2018-10-18 17:26:32 |
 赞(
赞( 操作
操作

{kind=link}
{kind=link}