转自公众号大数据文摘
我们常把机器学习描述为一种使用数据模式标记事物的神奇技术。听起来艰涩,但事实上,拨开层层概念,机器学习的核心简单到令人尴尬。
本文将用一个葡萄酒是不是好喝的例子,让你迅速了解整个机器学习的技术过程。

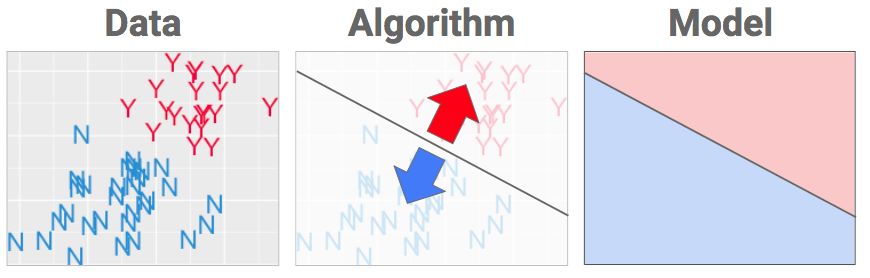
数据
想象我们品尝了50种葡萄酒,并且为了方便展示,我在下面进行了数据可视化。每款酒的数据包括年份、分数,再加上我们想学的特征:Y代表好喝,N代表不好喝。
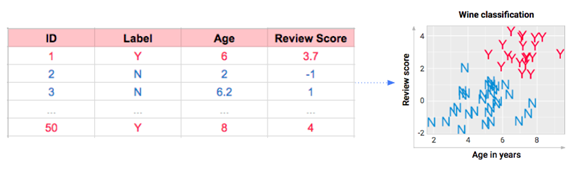
上图的左侧是表格模式,有图展示信息的方式更加友好。如果你想要使用数据集术语,比如特性和实例,来描述这些数据,以下是一个指南。
算法
通过选择要使用的机器学习算法,我们可以得到我们想要的输出。在这个问题中,算法的全部工作就是把上图中红色的东西和蓝色的东西分开。
机器学习算法的目的是在数据中选择最合理的位置设置边界。
如果你想划一条线,恭喜你!你刚刚发明了一个叫作感知器机器学习算法。是的,这么科幻的名字描述的其实是一种非常简单的概念!随着学习的深入,你会发现被机器学习中的术语所吓到稀松平常,但它们的内涵通常都配不上这个名字的复杂度。
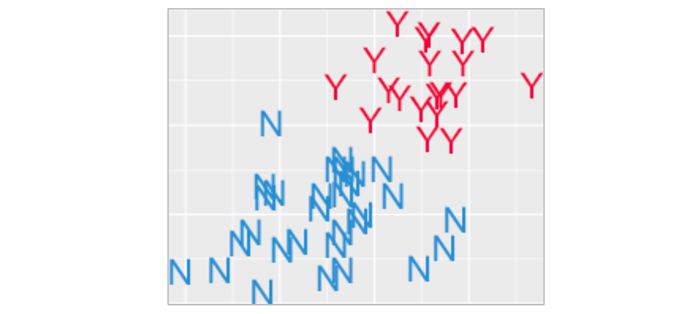
如果是你,你将如何分开蓝色和红色?
可能你会说一条平直的线就够了。但我们的目标是把Y和N分开,而不是装饰性的地平线。
机器学习算法的目的是选择最合理的位置设置边界,这是由据点到达的位置来决定的。但它是怎么做到的呢?一般来说,是通过优化一个目标函数。
优化
如果计划给自己的博客文章做优化,我们可以这样想:目标函数就像棋盘游戏得分的规则,优化它就是想出如何玩才能让玩得更好并赢到最好的分数。

目标函数(损失函数)就像棋盘游戏的积分系统。
在机器学习的传统中,我们更喜欢棍棒而不是胡萝卜--分数是对错误的惩罚(在分界线的错误一侧贴上标签),而游戏就是去尽可能的得到尽量少的错误分数。这就是为什么ML中的目标函数往往被称为“损失函数”,即目标是最小化损失。
现在我们可以回到最开始的问题了,把你的手指水平地对着屏幕并不断画出直线,直到你得到一个零分的结果(即没有一点能够逃避你充满力量的、愤怒的手指所画出来的线)。
希望您找到的解决方案是这样的:
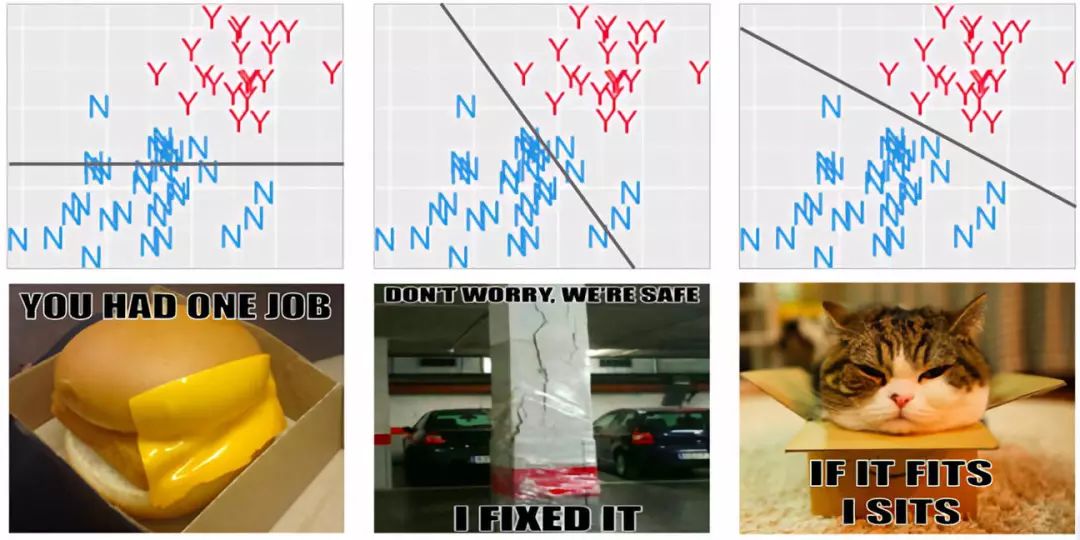
希望你能聪明地意识到,在上面的三个解决方案中,最右边的是最好的。
如果你喜欢多样性,你会喜欢算法的。因为它们太多了,并且它们之间的不同之处往往在于它们如何在不同的位置上尝试分离边界。
在优化问题中,以微小的增量旋转边界显然是不靠谱的。还有更好的方法可以更快地到达最优位置。 一些研究人员毕生致力于想出在最少的转变中获得最好的边界位置的方法,不管数据域看起来有多不正常(由你的输入决定)。
另一个变化的来源是边界的形状。原来地边界不一定是直的。不同的算法使用不同的边界。
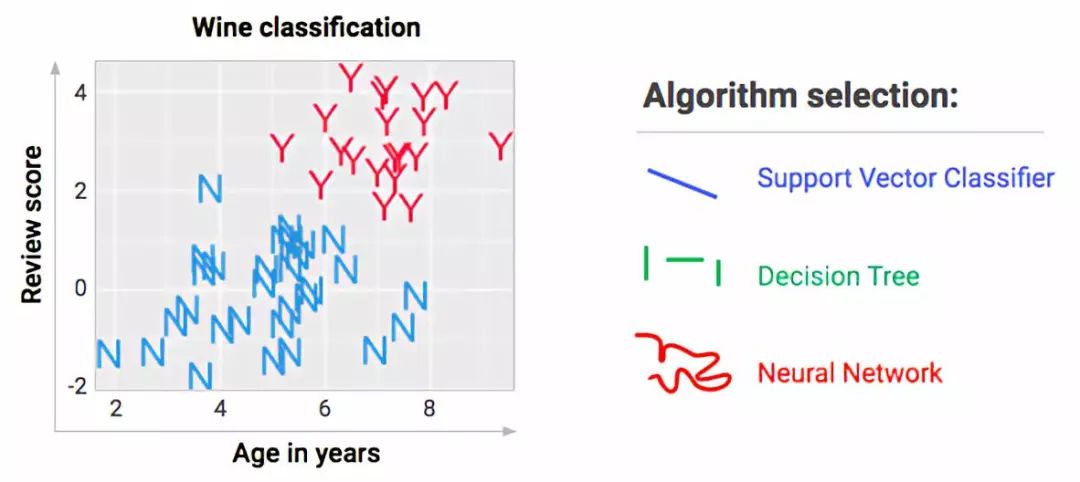
当我们选择这些各种各样的名称时,我们只是选择在标签之间绘制的边界的形状,即在选择我们要用一条对角线,多条水平和竖直线还是灵活的波形短线去分隔它们?
潮人算法
如今,没有一位数据科学家再使用简陋的直线了。灵活多变的形状在当今大多数的人群中都很受欢迎的(你可能知道,例如神经网络——虽然他们没有太多的神经,他们的名字在半个多世纪前就被命名了,而且似乎没有人喜欢我的建议——就是我们把他们重新命名为“瑜伽网络”或“多层数学运算”)。

如果你一直期望的是有魔力的算法,那么早一点失望,就早一点清醒,当这些科幻迷信般的兴奋褪去,你才会新生出做真正酷的事情的笃定。机器学习本身可能平淡无奇,但是你可以用它做的事情却可以惊天动地,它能让你写出你完全想不到的程序代码,让你可以自动化那些无法言喻的过程,不要嫌弃机器学习的简单,杠杆也很简单,但是它可以撬动整个世界
除了这种市场营销式的用其他线性算法和智能神经网络做对比,更值得我们关注的是这些算法的柔韧扩展性。虽然其他算法在处理数据拉伸变换时不那么智能,但是天底下没有免费的午餐,运用神经网络也是要付出昂贵代价的(下文有更多说明),所以不要相信那些宣称神经网络永远是最完美方案的人。
神经网络也可以叫做瑜伽网络
这些奇奇怪怪的算法名称不过是告诉你什么形状的分界线会被放入你的数据集中。如果你是一位致力于将机器学习投入实际应用的学习者,那么记不住这些名词也没关系。实际操作时,你只需要把你的数据扔到尽可能多的算法里去尝试,然后重复训练那些看起来最有希望的算法。证明巧克力布丁最好的方法就是吃掉它,所以我们开始享用吧。

就算你认认真真的学习了资料,你也不可能第一次就碰巧拿到正确的算法。别焦虑,这不是只有标准答案的竞赛。尽管抱着玩的心态,敲敲打打,多多琢磨。对机器学习这个布丁的证明就隐藏在吃透它的过程里-这套算法适用于新的数据吗?你不用担心算法是如何工作的,将这个问题留给专门设计新算法的研究者们吧(而且你最终会越来越熟悉这些术语,就像你会记住那些播烂了的肥皂剧里的角色一样,久而久之,你会记住所有这些拗口的术语)
模型
一旦确立好分界线,算法就结束了。而你从算法中得到的就是你一直想要的:模型。所谓模型不过是“计算机菜谱”的酷炫叫法,它实际上就是计算机用来将数据转换成决策的指令。当我再次展示一瓶新的葡萄酒时,如果数据落在蓝色区域,就被命名为蓝。落在红色区域?那就命名为红。
标签
一旦你将刚出炉的模型投入使用,在向计算机输入酒龄,评级分数后,你的系统就会查找这瓶红酒数据对应的区域,并输出一个标签。
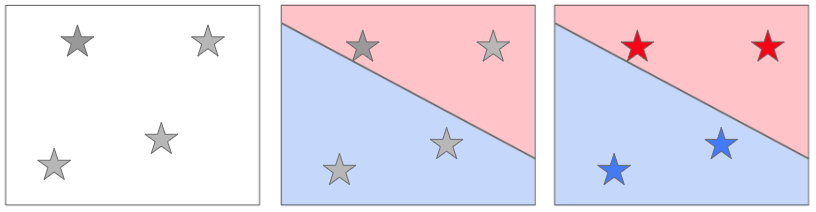
当我有四瓶新的葡萄酒时,我只需要将输入的数据和菜单上的红蓝区域匹配,并插上标签,看,就是这么简单!
那我们怎么知道这个算法到底可行不可行呢?就像检验一群敲击键盘的猴子是不是在写莎士比亚诗集一样,我们可以通过检查输出来判断。
吃掉布丁才可以证明布丁
用大量的新数据来检测你的系统,确保你的系统在这些数据上都运行良好。事实上,不管是面对一个算法还是一个拿着计算机菜谱找到你的程序员,你都应该用大量的数据去检测。
这是我另一篇文章里一份非常形象的总结:
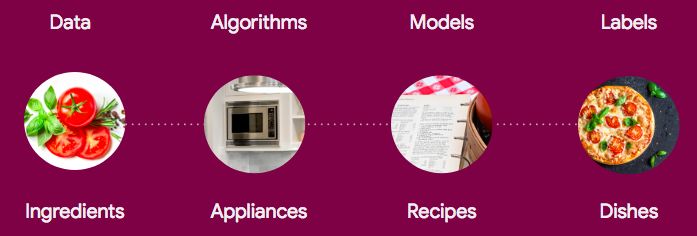
诗人一般的机器学习
如果这句话让你很困惑,也许下面这个类比你会更容易接受:一位诗人挑选了一种方法(算法)来组织纸面上的词语,这种方法决定了最后诗歌的形式(边界形状)
例如决定这首诗是日式俳句还是十四行诗。一旦在十四行诗这个骨架上最优化地添加词语,使其充实丰满,那它就会变成一首诗(模型)。至于诗歌为什么会变成计算机菜谱,饶了我吧-我也不知道,但是我非常欢迎其他的建议。不管怎样,这个类比的其他部分还是说得通的。
机器学习模型VS传统编程代码
不得不指出的是机器学习的这份菜谱和程序猿着眼于问题而手工敲出的代码没有很大区别。忘掉对机器学习人格化的幻想吧,机器学习模型和常规代码在概念上没有区别。是的,就是那些脑袋里充满主观意见和咖啡因的程序猿手写出的菜谱代码
不要到处嚷嚷着“再训练”-这个术语不过是指在加入新数据样本后需要再跑一次算法来调整模型边界而已。但是这个名词让机器学习听起来像一个活的生物,好像它天生就和那些标准程序猿产品不一样,事实上,程序猿也可以好好坐下来根据新的信息来手工调整代码,如果你觉得你的机器学习系统可以加快更新迭代速度,那么就把时间好好投资在测试系统上,要不然还不如跑一个睡眠程序让你自己好好休息一下。
这就是关于机器学习的一切?
差不多啦,机器学习的核心部分就是安装各种程序包,然后捋顺你杂乱无章、毛发丛生的数据怪兽,便于挑剔的算法在你的数据集上运行。
接着就是永无止境的调整代码设置(不要让“超参数调优”这个听起来高大上的名字吓到了你)直到你欢呼:好啦!一个模型完成啦! 但是一旦你的模型在新的数据集上表现不好,你就不得不重新回到画板前,一遍又一遍的调试,直到拨云见日,你的方案终于可以拿得出手了。这就是为什么要雇用失败承受力强的人来做这件事
如果你一直期望的是有魔力的算法,那么早一点失望,就早一点清醒,当这些科幻迷信般的兴奋死去时,我们才会新生出做真正酷的事情的信念。机器学习本身可能平淡无奇,但是你可以用它做的事情却是惊天动地,它可以让你写出你完全想不到的程序代码,让你可以自动化那些无法言喻的过程,不要嫌弃机器学习的简单,杠杆也很简单,但是它可以撬动整个世界。
该贴被liuliying930406编辑于2018-10-17 14:49:25
 发起投票
发起投票









 加好友
加好友 发消息
发消息 2018-10-17 14:47:59 |
2018-10-17 14:47:59 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}