转发自公众号 AI科技评论
AI 科技评论按:一提起RNN,我们最容易想到的实现就是LSTM + attention。LSTM 作为经典的网络结构可谓是老当益壮,而另一方面注意力机制过于常见,我们甚至会觉得它是「理所当然的」。但其实注意力机制其实并不是唯一一种网络增强的方式。这篇Distill.pub 博客的文章就带我们重温了包括注意力在内的多种网络增强方式,它们侧重的方向不一样,也就方便研究/开发人员们按照自己的实际需求进行选取。AI 科技评论编译如下。
循环神经网络(RNN)是深度学习技术中十分重要的一类模型,它让神经网络能够处理文本、音频和视频等序列数据。人们可以用循环神经网络将一个序列归结为一个高级的理解模式,从而对序列进行标注,甚至从头开始生成一个新的序列。
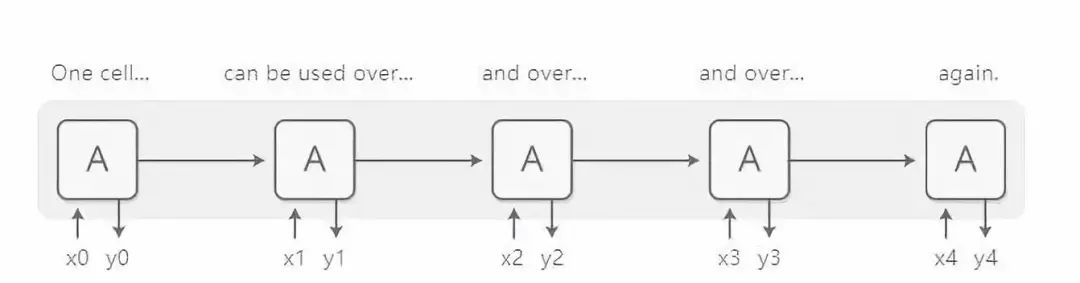

基本的RNN 设计过程需要对棘手的长序列进行处理,但是一种特殊的RNN 变体——LSTM(long short-term memory,长短期记忆网络)可以在这种情况下很好地工作。人们发现这些模型十分强大,能够在包括机器翻译、语音识别和图像理解(看图说话)等许多任务中取得非常好的效果。因此,在过去的几年里,循环神经网络已经被广泛使用。
随着人们对循环神经网络的研究越来越深入,我们已经看到越来越多的人试图用一些新的特性来增强循环神经网络。有四个方向的改进特别令人激动:
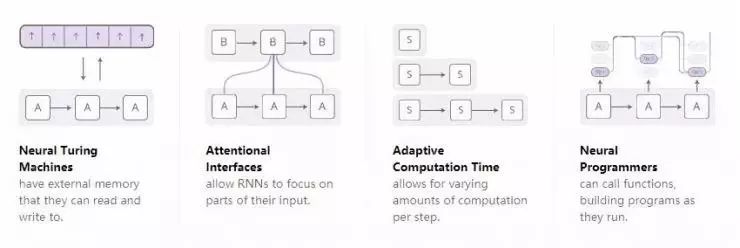
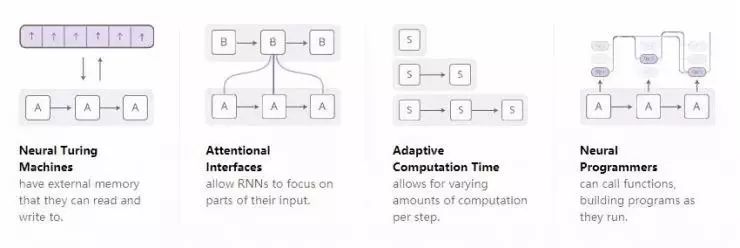

这些技术中,每一项技术都对神经网络有很大的提升。然而,真正炫酷的是,这些技术还能结合在一起使用,而且现有的这些技术似乎都只是广阔的研究空间中的一叶扁舟。此外,它们都依赖于同样的底层技术——注意力机制,从而发挥作用。
神经图灵机
神经图灵机[2] 将RNN 与外部存储单元相结合。由于向量是自然语言在神经网络中的表现形式,所以存储单元中的内容是一组向量:

但是对神经图灵机的读写的工作方式是怎样的呢?真正的挑战是,我们需要让它们可微。特别是,我们需要让它们对于我们读和写的位置可微,从而让我们学会在哪里进行读写操作的。由于存储地址在根本上是离散的,要让它们可微是十分困难的。为此,神经图灵机采取了一种很聪明的解决方案:在每一步操作中,它们会在存储单元的所有位置进行读写,只是程度不同而已。
举例而言,让我们重点关注读操作。RNN 并没有指定一个特定的读取位置,而是输出了一个「注意力分布」,它描述了我们对于不同的存储位置关注程度的分布情况。由此得到的读操作的结果就是一个加权和。

类似地,我们也会以不同程度在存储单元中的各个位置进行写操作。我们再次用一个注意力分布描述我们在每个位置写入了多少内容。我们通过使存储单元中每个位置的新值成为旧存储内容和新写入的值的凸组合来做到这一点,而旧的存储内容和新值之间的位置取决于注意力权重。
但是,神经图灵机是如何确定应该将注意力集中在存储单元的哪些位置上呢?实际上,它们采用了两种不同方法的组合:基于内容的注意力机制和基于位置的注意力机制。基于内容的注意力机制使神经图灵机可以在他们的存储器中进行搜索并重点关注于他们所寻找的目标相匹配的位置,而基于位置的注意力机制则使存储单元中注意力的相对运动成为了可能,使神经图灵机能够循环。

这种读写能力使得神经图灵机能够执行许多简单的算法,而不仅限于神经网络范畴。例如,它们可以学习在存储单元中存放一个长的序列,然后对其反复进行循环操作。当它们这样做的时候,我们可以看到他们在哪些位置执行了读写操作,以便更好地理解他们在做什么:

你可以在[3]中查看更多的实验结果。上图是基于重复的复制实验得出的。
它们还可以学会模仿查表法,甚至学着对数字进行排序(尽管采取了一些投机取巧的方法)!另一方面,有时他们面对一些很基础的工作也会无能为力,比如对数字进行加法或乘法运算。
自从最原始的神经图灵机论文发表后,相继涌现了一大批在相关领域取得激动人心的研究进展的论文。神经GPU[4] 解决了神经图灵机无法对数字进行加法和乘法运算的问。Zaremba 和Sutskever 等人[5]使用强化学习代替了最原始的神经图灵机中使用的可微的读写技术来训练神经机器翻译。神经随机存取存储器(NRAM)是基于指针工作的。目前,一些论文已经对栈和队列这种可微的数据结构进行了探究[7,8]。而记忆网络[9,10](memory networks)则是另一种解决类似问题的方法。
从某种客观意义上来讲,这些模型可以执行的许多任务(例如学会如何对数字做加法),并不是十分困难。对于传统的编程技术说,这些任务可以说是小菜一碟。但是神经网络可以处理许多其他的问题,而目前像神经图灵机这样的模型的能力似乎仍然收到了很大限制,没有被完全开发出来。
代码
这些模型有许多开源的实现版本。神经图灵机的开源实现有Taehoon Kim(Tensorflow 版,https://github.com/carpedm20/NTM-tensorflow )、Shanwn(Theano 版,https://github.com/shawntan/neural-turing-machines )、Fumin(Go 版,https://github.com/fumin/ntm )、Kai Sheng(Torch 版,https://github.com/kaishengtai/torch-ntm )、Snip(Lasagne 版,https://github.com/snipsco/ntm-lasagne )等人的版本。神经GPU 代码是开源的,并已经被TensorFlow 的模型库囊括了进去(https://github.com/tensorflow/models/tree/master/neural_gpu )。记忆网络的开源实现包含Facebook(Torch/Matlab 版,https://github.com/facebook/MemNN )、YerevaNN(Theano 版,https://github.com/YerevaNN/Dynamic-memory-networks-in-Theano )、Taehoon Kim(TensorFlow 版,https://github.com/carpedm20/MemN2N-tensorflow )等人的版本。
注意力机制
当我们翻译一个句子时,我们会特别注意当前翻译的单词。当我们转录一段录音时,我们会仔细听我们正努力写下的章节。如果你要我描述我所坐的房间,我会在描述的时候看看周围的物体。
神经网络使用注意力机制实现同样的行为,专注于整个环境中所获的的信息的一部分。例如,RNN可以处理另一个RNN 的输出。在每一个时间步上,带注意力机制的RNN 都会关注另一个RNN 的不同位置上的内容。
我们希望注意力机制是可微的,这样我们就可以学到重点关注什么位置上的内容。为了做到这一点,我们奖使用和神经图灵机一样的技术:我们关注所有的位置,只是关注的程度不同罢了。

注意力分布通常是由基于内容的注意力机制生成的。我们用来操作的RNN 会生成一个搜索词描述它想要关注的位置。每一项都会与搜索词进行点乘从而产生一个得分,该得分将描述其与搜索词的匹配程度。这个得分将作为输入送给Softmax 函数,用来创建注意力分布。

在RNN 之间应用注意力机制的一个场景是机器翻译[11]。一个传统的序列到序列(Seq2Seq)的模型必须将整个输入归结为一个单一的向量,然后将其反向扩展得到翻译结果。注意力机制通过使RNN 能够处理输入来传递它所看到的每一个单词信息,然后在生成输出的RNN 中将注意力集中在相关的单词上。
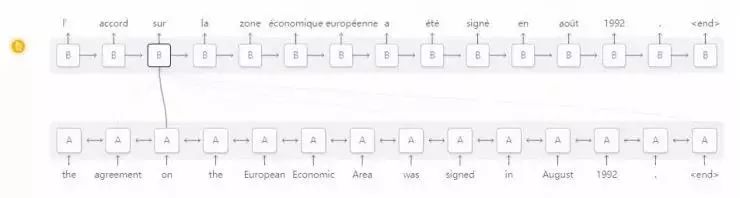

图片来源:Bahdanau 等人于2014年发表的论文中的图3(https://arxiv.org/pdf/1409.0473.pdf )
这种RNN 之间的注意力机制已经有许多其它的应用场景。它能够在语音识别[12]中被使用,使一个RNN 能够处理音频信息,然后让另一个RNN 能够浏览它,在它生成音频相应的文字时将注意力放在相关的部分上。

图片来源:Chan 等人于2015 年发表的论文(https://arxiv.org/pdf/1508.01211.pdf)。
这种注意力机制其它的应用还包括文本解析[13],这时注意力机制让模型能够在生成解析树时对单词进行扫描。而在对话建模[14]任务中,注意力机制使模型能在生成回应文字时,重点关注对话前面相关求的内容。
注意力机制还可以用在卷积神经网络和循环神经网络之间的接口上。这里的注意力机制使RNN能够在每一步关注图像上的不同位置。这种注意力机制的一个流行的应用场景是「看图说话」。首先,一个卷积网络会对图片进行处理从而抽取高级特征;接着会运行一个RNN 生成对图像的描述。当它生成描述中的每个单词时,RNN 会关注卷积神经网络对图像相关部分的解释。我们可以用下图显示地可视化这个过程:

图片来源:(arXiv preprint arXiv:1502.03044, Vol 2(3), pp. 5. CoRR.)
更广泛地说,当我们想要与一个在输出中有重复结构的神经网络对接时,可以使用注意力接口。
人们发现注意力接口是一种极具通用价值并且十分强大的技术,并且正在被越来越广泛地使用。
自适应计算时间
标准的RNN 在每个时间步上执行相同数量的计算。这似乎并不符合直觉。当然,我们要处理的问题变得更加复杂时,人们是否应该再多考虑考虑呢?此外,标准RNN 还将其操作长度为n 的序列的时间复杂度限制为O(n)。
自适应计算时间[15]是一种让RNN能够在每一步之行不同数量的计算的方法。大体的思路很简单:它让RNN 能在每个时间步上进行多步计算。
为了让网络学习需要计算多少步,我们希望步骤的数量可微。我们用我们曾经使用过的技术来实现这一点:我们并不运行离散数量的步骤,而是对运行的步数使用了一个注意力分布。它的输出是每个步骤的输出的加权组合。

上图还忽略了一些更多的细节。下图是在一个时间步上包含三个计算步骤的完整示意图:

此图描述的计算过程有些复杂,所以让我们一步步地分析它。在高层,我们仍然运行RNN 并输出一个状态的加权组合:

每一个计算步骤的权重都由一个「缓冲神经元」决定。它是一种能够观察RNN 的状态并给出一个缓冲权重的sigmoid 神经元,我们可以认为它是我们应该在这一步停下来的概率。

我们对于缓冲权重的总预算上限为1,接着我们根据下图最上面一行的计算流程进行计算(从1 开始,每一步减去相应的值)。当它变得小于epsilon 时,我们就停止计算。

当我们停下来时,可能还会有一些在缓冲预算之外还没有计算完的部分,这是因为我们在其小于epsilon 时就会停止计算。我们该如何处理这种情况呢?从技术上讲,它被赋予了未来可以继续计算的步骤,而我们现在并不想计算它,因此我们将现在的状态定义为最后一步。

当我们训练自适应计算时间模型时,可以在损失函数中添加一项「思考成本」(ponder cost),用来惩罚模型的累积计算时间。这一项越大,就会更加因为降低计算时间而降低性能,达到折中的目的。
自适应计算时间是一种非常新的想法,但是我们相信它和类似的思想都是非常重要的。
代码
目前唯一的「自适应计算时间」模型的开源代码似乎是Mark Neumann的版本(TensorFlow 版,https://github.com/DeNeutoy/act-tensorflow)。
神经网络编程器
神经网络在许多任务上的表现都非常出色,但它们又是也很难做到一些基本的事情。比如算术对于神经网络就很困难,而这对于普通的计算方法是轻而易举的。如果有一种方法可以将神经网络与普通的编程方法融合在一起,就会取得最大的双赢局面。
神经网络编程器[16]是一种解决该问题的方法。它会学着创建程序来解决这个问题。事实上,它能在不需要正确的程序实例范本的情况下生成这样的程序。它会发现要想完成某种任务,做为手段,需要如何生产出程序。
论文中实际的模型通过生成类SQL 程序查询表格来回答这个问题。然而,这种环境下的大量细节让它变得有些复杂。所以我们不妨从想象一个稍微简单一点的模型开始,它给出了一个算术表达式,并生成了一个模型来评估它。
生成的程序是一个操作序列。每个操作都被定义为对过去操作的输出进行操作。因此,一个操作可能类似于「将两步前的操作的输出和一步前的操作的输出相加」。它更像是一个Unix 管道,而不是一个拥有被赋值并被读取的变量的程序。

该程序由控制器RNN 一次生成一个操作。在每个步骤中,控制器RNN都会输出下一个操作应该是什么的概率分布。例如,这个概率可以用来模拟:我们可能非常确定我们想要在第一个时间步上执行加法,然后在决定我们是否需要在第二步执行乘法或除法的时候会很艰难,等等…

现在,最终得出的操作的分布可以被我们评估。我们并不是在每一步运行一个操作,而是采用了普遍使用的注意力技巧,同时运行所有的操作,再根据我们执行这些操作的概率作为权重对所有的输出一起取平均。

只要我们能够通过这些操作定义导数,程序的输出在概率上就是可微的。接着,我们可以定义一个损失函数,训练神经网络生成给出正确答案的程序。这样一来,神经网络编程器就学会了在没有正确程序范例的情况下生成程序。唯一的监督信息就是程序应该产生的返回值。
这就是神经网络编程器的核心思想,但是论文中的版本回答了关于表的问题,而不是关于算术表达式。下面我们还将给出一些实用的小技巧:
多种数据类型:神经网络编程器中的许多操作都会处理除标量值之外的其他类型的数据。一些操作输出选中的表的列或者选中的单元格。只有相同类型的输出才能被合并到一起。
参考输入:神经网络编程器需要回答类似于「有多少个人口超过1 百万人的城市?」为了使回答这种问题更加容易,一些操作允许网络参考他们正在回答的问题中的常量,或者列的名字。这种参考是由于注意力机制发生的,就像指针网络[17]。
神经网络编程器并不是让神经网络生成程序的唯一途径。另一种好方法是神经网络编程器-解释器[18],他可以完成很多有趣的任务,但是需要正以确程序作为监督信息。
我们认为,这种弥合传统编程和神经网络之间差距的一般空间是非常重要的。虽然神经网络编程器显然不是最终的解决方案,我单们认为有很多重要的经验教训可以从中学到。
代码
最新版本的用于问答的神经网络编程器(https://openreview.net/pdf?id=ry2YOrcge )已经被其作者开源,并且可以作为TensorFlow 模型获取(https://github.com/tensorflow/models/tree/master/neural_programmer )。而神经网络编程器-解释器也有由Ken Morishita编写的Keras 版本(https://github.com/mokemokechicken/keras_npi )。
整体把握
从某种意义上说,一个人类拿着一张纸,比没有纸的人聪明得多。一个有数学符号的人可以解决他们不能解决的问题。使用电脑使我们能够做出不可思议的壮举,否则它们将远远超出我们的能力范围。
一般来说,很多有趣的智力形式似乎是人类的创造性启发式直觉和一些更加直观具体的媒介之间的相互作用,如语言或方程式。有时,媒介是客观存在的东西,为我们储存信息,防止我们犯错误,或者执行繁琐的计算任务。在其他情况下,媒介是我们在脑海中操纵的一个模型。无论如何,这对于智能来说都是至关重要的。
最近机器学习的结果已经开始有了这种味道,将神经网络的直觉和其他东西结合起来。其中一种方法就是人们所说的「启发式搜索」。例如,AlphaGo [19]有一个关于围棋如何工作的模型,并且探索了在神经网络直觉指导下如何玩这个游戏的模型。类似地,DeepMath [20]利用神经网络表征操作数学表达式的直觉。我们在本文中谈到的「增强的RNN」是另一种方法,将RNN 连接到专门设计的媒介上,以提高它们的泛化能力。
与媒介的相互作用自然包括「采取一系列行动、进行观察、再采取进一步的行动」。在这里,我们面临着一个巨大的挑战:我们如何学习应该采取怎样的行动?这听起来是个强化学习问题,我们当然可以采用这样的做法。但是,强化学习技术实际上是解决该问题最复杂的版本,而且这种解决方案很难使用。注意力机制的精妙之处在于,它使我们能够更容易地通过对部分位置以不同程度执行所有的动作来解决这个问题。这是因为我们可以设计像神经图灵机这样的存储结构使我们能进行细微的操作,并且使该问题可微。强化学习让我们采取一条单一的解决路径,并且试着从中学到知识。注意力机制则在每一个选择的交叉口采取了各个方向的动作,并最终将各条路径的结果合并在一起。
注意力机制的一个主要的缺点是,我们必须在每一步上采取「动作」。由于我们会进行进行增加神经图灵机中的存储单元等操作,这会导致计算开销直线上升。可以想到的解决方法就是让你的注意力模型变得稀疏一些,这样以来你就只需要对一部分存储单元进行操作。然而,这仍然是具有挑战性的,因为你可能想要让你的注意力模型依赖于存储单元的内容,而这样做会令你不得不查看每一个存储单元。我们已经观察到,目前有一些初步的工作在常识解决这个问题,例如[21] ,但是似乎还有许多工作有待探索。如果我们真的能做出这样的在次线性时间复杂度内的注意力机制的工作,这种模型会变得非常强大!
增强的循环神经网络和注意力机制的底层技术是如此令人激动!我们期待着这个领域有更多的新技术涌现出来!
参考文献
1. Understanding LSTM Networks [link](http://colah.github.io/posts/2015-08-Understanding-LSTMs)
Olah, C., 2015.
2. Neural Turing Machines
Graves, A., Wayne, G. and Danihelka, I., 2014. CoRR, Vol abs/1410.5401.
3. Show, attend and tell: Neural image caption generation with visual attention
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R.S. and Bengio, Y., 2015. arXiv preprint arXiv:1502.03044, Vol 2(3), pp. 5. CoRR.
4. Neural GPUs Learn Algorithms
Kaiser, L. and Sutskever, I., 2015. CoRR, Vol abs/1511.08228.
5. Reinforcement Learning Neural Turing Machines
Zaremba, W. and Sutskever, I., 2015. CoRR, Vol abs/1505.00521.
6. Neural Random-Access Machines
Kurach, K., Andrychowicz, M. and Sutskever, I., 2015. CoRR, Vol abs/1511.06392.
7. Learning to Transduce with Unbounded Memory
Grefenstette, E., Hermann, K.M., Suleyman, M. and Blunsom, P., 2015. Advances in Neural Information Processing Systems 28, pp. 1828—1836. Curran Associates, Inc.
8. Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets
Joulin, A. and Mikolov, T., 2015. Advances in Neural Information Processing Systems 28, pp. 190—198. Curran Associates, Inc.
9. Memory Networks
Weston, J., Chopra, S. and Bordes, A., 2014. CoRR, Vol abs/1410.3916.
10. Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
Kumar, A., Irsoy, O., Su, J., Bradbury, J., English, R., Pierce, B., Ondruska, P., Gulrajani, I. and Socher, R., 2015. CoRR, Vol abs/1506.07285.
11. Neural machine translation by jointly learning to align and translate
Bahdanau, D., Cho, K. and Bengio, Y., 2014. arXiv preprint arXiv:1409.0473.
12. Listen, Attend and Spell
Chan, W., Jaitly, N., Le, Q.V. and Vinyals, O., 2015. CoRR, Vol abs/1508.01211.
13. Grammar as a foreign language
Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I. and Hinton, G., 2015. Advances in Neural Information Processing Systems, pp. 2773—2781.
14. A Neural Conversational Model
Vinyals, O. and Le, Q.V., 2015. CoRR, Vol abs/1506.05869.
15. Adaptive Computation Time for Recurrent Neural Networks
Graves, A., 2016. CoRR, Vol abs/1603.08983.
16. Neural Programmer: Inducing Latent Programs with Gradient Descent
Neelakantan, A., Le, Q.V. and Sutskever, I., 2015. CoRR, Vol abs/1511.04834.
17. Pointer networks
Vinyals, O., Fortunato, M. and Jaitly, N., 2015. Advances in Neural Information Processing Systems, pp. 2692—2700.
18. Neural Programmer-Interpreters
Reed, S.E. and Freitas, N.d., 2015. CoRR, Vol abs/1511.06279.
19. Mastering the game of Go with deep neural networks and tree search
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Driessche, G.v.d., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T. and Hassabis, D., 2016. Nature, Vol 529(7587), pp. 484—489. Nature Publishing Group. DOI: 10.1038/nature16961
20. DeepMath - Deep Sequence Models for Premise Selection
Alemi, A.A., Chollet, F., Irving, G., Szegedy, C. and Urban, J., 2016. CoRR, Vol abs/1606.04442.
21. Learning Efficient Algorithms with Hierarchical Attentive Memory
Andrychowicz, M. and Kurach, K., 2016. CoRR, Vol abs/1602.03218.
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2018-10-12 16:55:20 |
2018-10-12 16:55:20 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}