前言
我发现有很多程序员面试前都是准备地好好的,什么疑难杂症,未解之谜都是准备得妥妥的,张口就来。
反而到了最容易的Java基础的时候,各种翻车(可能是觉得基础的内容太简单没有花精力),本来是能够拿到更高的薪资,就因为基础没有回答好,被抓住当成借口又砍了好几K,实在是得不偿失。
所以今天给大家分享一份Java基础的面试题汇总以及解析,以便大家更好地应对面试,冲击更高薪资!

1. String类为什么是final的
主要是为了”安全性“和”效率“的缘故,因为:
1、由于String类不能被继承,所以就不会没修改,这就避免了因为继承引起的安全隐患;
2、String类在程序中出现的频率比较高,如果为了避免安全隐患,在它每次出现时都用final来修饰,这无疑会降低程序的执行效
率,所以干脆直接将其设为final一提高效率;
2. HashMap的源码,实现原理,底层结构。
HashMap就是数组+链表的组合实现,每个数组元素存储一个链表的头结点,本质上来说是哈希表“拉链法”的实现。
HashMap的链表元素对应的是一个静态内部类Entry,Entry主要包含key,value,next三个元素
主要有put和get方法,put的原理是,通过hash%Entry.length计算index,此时记作Entry[index]=该元素。如果index相同
就是新入的元素放置到Entry[index],原先的元素记作Entry[index].next
get就比较简单了,先遍历数组,再遍历链表元素。
null key总是放在Entry数组的第一个元素
解决hash冲突的方法:链地址法
再散列rehash的过程:确定容量超过目前哈希表的容量,重新调整table 的容量大小,当超过容量的最大值时,取
Integer.Maxvalue
3. 什么是Java集合类?说说你知道的几个Java集合类。
集合类存放于java.util包中。
集合类存放的都是对象的引用,而非对象本身,出于表达上的便利,我们称集合中的对象就是指集合中对象的引用(reference)。
集合类型主要有3种:set(集)、list(列表)和map(映射)。
集合接口分为:Collection和Map,list、set实现了Collection接口
4. 描述一下ArrayList和LinkedList各自实现和区别
ArrayList,LinkedList都实现了java.util.List接口,
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
5. Java中的队列都有哪些,有什么区别
Java中的队列都有哪些,实际上是问queue的实现有哪些,如:ConcurrentLinkedQueue、LinkedBlockingQueue 、
ArrayBlockingQueue、LinkedList。
关于ConcurrentLinkedQueue和LinkedBlockingQueue:
LinkedBlockingQueue是使用锁机制,ConcurrentLinkedQueue是使用CAS算法,虽然LinkedBlockingQueue的底层获取锁也是使用的CAS算法
关于取元素,ConcurrentLinkedQueue不支持阻塞去取元素,LinkedBlockingQueue支持阻塞的take()方法,如若大家需要ConcurrentLinkedQueue的消费者产生阻塞效果,需要自行实现
关于插入元素的性能,从字面上和代码简单的分析来看ConcurrentLinkedQueue肯定是最快的,但是这个也要看具体的测试场景,我做了两个简单的demo做测试,测试的结果如下,两个的性能差不多,但在实际的使用过程中,尤其在多cpu的服务器上,有锁和无锁的差距便体现出来了,ConcurrentLinkedQueue会比LinkedBlockingQueue快很多:ConcurrentLinkedQueuePerform:在使用ConcurrentLinkedQueue的情况下100个线程循环增加的元素数为:33828193
LinkedBlockingQueuePerform:在使用LinkedBlockingQueue的情况下100个线程循环增加的元素数为:33827382
6. 反射中,Class.forName和classloader的区别
Java中Class.forName和classloader都可以用来对类进行加载。
Class.forName除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classloader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
Class.forName(name,initialize,loader)带参数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象。
7. Java7、Java8的新特性(baidu问的,好BT)
以下特性为个人比较关注的特性,并不齐全;想了解更多,请自行搜索官方文档。
Java7特性:
1.switch case可以使用String,原来只能用int和char;
2.支持2进制0b开头;支持数字中间有下划线,解析时自动剔除;
3.一次抓多个异常;用|隔开;
4.try-with-resource,在try中打开资源,系统自动在使用完后关闭;
5. Map<String, List<String>> anagrams = new HashMap<>(); 对抗Google的guava.
6.集合类可以像js中的数组一样赋值和引用了。
List<String> list = ["item"];
String item = list[0];
Set<String> set = {"item"};
Map<String, Integer> map = {"key" : 1};
int value = map["key"];
7. 把字符串常量池从permgen区移到了堆区;导致String.intern()方法在1.7之前和之后表现出现不一致;
Java8特性:
1.lambda表达式;
2.新增stream,Date,Time,Base64工具类;
3.使用metaspace,元空间替代permgen区;
4.类依赖分析器:jdeps,可以以包,目录,文件夹作为输入,输出依赖关系,没有的会显示 not found
5.jjs,可以执行JavaScript代码;
8. Java数组和链表两种结构的操作效率,在哪些情况下,哪些操作的效率高
数组在随机访问数据、随机增加数据、随机删除数据的执行效率上比链表的效率高,数据量越小,两者之间效率的差距越小,数据量越大差距越大。
9. Java内存泄露的问题调查定位:jmap,jstack的使用等等
详细解析:https://blog.csdn.net/sinat_29581293/article/details/70214436
10. string、stringbuilder、stringbuffer区别
这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。
首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String最慢的原因:
String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。
2. 再来说线程安全
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
3. 总结一下
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
11.hashtable和hashmap的区别
1. 存储结构

HashMap的存储规则:
优先使用数组存储, 如果出现Hash冲突, 将在数组的该位置拉伸出链表进行存储(在链表的尾部进行添加), 如果链表的长度大于设定值后, 将链表转为红黑树.
HashTable的存储规则:
优先使用数组存储, 存储元素时, 先取出下标上的元素(可能为null), 然后添加到数组元素Entry对象的next属性中(在链表的头部进行添加).
出现Hash冲突时, 新元素next属性会指向冲突的元素. 如果没有Hash冲突, 则新元素的next属性就是null
描述的有点模糊, 贴出源码会清晰一点:
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
2. 扩容方式

3. 关于null值

4. 线程安全

13 .异常的结构,运行时异常和非运行时异常
大神的解释:https://blog.csdn.net/qq_27093465/article/details/52268531
14. String a= “abc” String b = “abc” String c = new String(“abc”) String d = “ab” + “c” .他们之间用 == 比较的结果
传送门:https://blog.csdn.net/qq_36381855/article/details/79686812
15. String 类的常用方法
String类中提供了大量的操作方法,这里例举13种关于String类常用的方法供大家参考。参考代码如下:
package cn.mc;
public class StringTestMc {
private String str = "helloWorld";
public void tocharyArry() {
char c[] = str.toCharArray();
for (int i = 0; i < c.length; i++) {
System.out.println("转为数组输出:" + c[i]);
}
}
public void tocharAt() {
char c = str.charAt(3);
System.out.println("指定字符为:" + c);
}
public void tobyte() {
byte b[] = str.getBytes();
System.out.println("转换成byte数组输出为:" + new String(b));
}
public void tolength() {
int l = str.length();
System.out.println("这个字符串的长度为:" + l);
}
public void toindexOf() {
int a1 = str.indexOf("e");// 查找字符e的位置
int a2 = str.indexOf("l", 2);// 查找l的位置,从第3个开始查找
System.out.println("e的位置为:" + a1);
System.out.println("l的位置为:" + a2);
}
public void totrim() {
String str1 = " hello ";
System.out.println("去掉左右空格后输出:" + str1.trim());
}
public void tosubstring() {
System.out.println("截取后的字符为:" + str.substring(0, 3));// 截取0-3个位置的内容
System.out.println("从第3个位置开始截取:" + str.substring(2));// 从第3个位置开始截取
}
public void tosplit() {
String s[] = str.split("e");// 按hello中的e进行字符串拆分
for (int i = 0; i < s.length; i++) {
System.out.println("拆分后结果为:" + s[i]);
}
}
public void tochange() {
System.out.println("将\"hello\"转换成大写为:" + str.toUpperCase());// 将hello转换成大写
System.out.println("将\"HELLO\"转换成大写为:"
+ str.toUpperCase().toLowerCase());// 将HELLO转换成小写
}
public void tostartsWithOrendWith()
{
if(str.startsWith("he"))//判断字符串是否以he开头
{
System.out.println("字符串是以he开头");
}
if(str.endsWith("lo"))
{
System.out.println("字符串是以lo结尾");
}
}
public void toequals()
{
String str3="world";
if(str.equals(str3))
{
System.out.println("这俩个String类型的值相等");
}
else
System.out.println("这俩个String类型的不值相等");
}
public void toequalslgnoreCase()
{
String str4="HELLO";
if(str.equalsIgnoreCase(str4))
{
System.out.println("hello和HELLO忽略大小写比较值相等");
}
}
public void toreplaceAll()
{
String str5=str.replaceAll("l", "a");
System.out.println("替换后的结果为:"+str5);
}
public static void main(String[] args) {
StringTest obj = new StringTest();
obj.tocharyArry();
obj.tocharAt();
obj.tobyte();
obj.tolength();
obj.toindexOf();
obj.totrim();
obj.tosubstring();
obj.tosplit();
obj.tochange();
obj.tostartsWithOrendWith();
obj.toequals();
obj.toequalslgnoreCase();
obj.toreplaceAll();
}
}
16. Java 的引用类型有哪几种
有这样一类对象:当内存空间还足够,则可保留在内存中;如果内存空间在gc之后还是非常紧张,则可抛弃这些对象。很多系统的缓存功能适合这样的场景,所以jdk1.2以后
java将引用分为了强引用、软引用、弱引用、虚引用四种,引用强度一次减弱。
强引用:类似Object a=new Object()这类,永远不会被回收。
软引用:SoftReference,当系统快要发生内存溢出异常时,将会把这些对象列入回收范围进行二次回收,如果这次回收还是没有足够内存,则抛出内存溢出异常。
弱引用:比软引用更弱,活不过下一次gc。无论当前内存是否足够,下一次gc都会被回收掉。
虚引用:又叫幻引用,最弱,一个对象时候有虚引用的存在,不会对它的生存时间构成影响,唯一目的就是能在这对象被回收以后收到一个系统通知。
17. 抽象类和接口的区别
接口是公开的,里面不能有私有的方法或变量,是用于让别人使用的,而抽象类是可以有私有方法或私有变量的,
另外,实现接口的一定要实现接口里定义的所有方法,而实现抽象类可以有选择地重写需要用到的方法,一般的应用里,最顶级的是接口,然后是抽象类实现接口,最后才到具体类实现。
还有,接口可以实现多重继承,而一个类只能继承一个超类,但可以通过继承多个接口实现多重继承,接口还有标识(里面没有任何方法,如Remote接口)和数据共享(里面的变量全是常量)的作用.
18. java的基础类型和字节大小
java数据类型 字节 表示范围
byte(字节型) 1 -128~127
boolean(布尔型) 1 true或false
short(短整型) 2 -32768~32767
char(字符型) 2 从字符型对应的整型数来划分,其表示范围是0~65535
int(整型) 4 -2147483648~2147483647
float(浮点型) 4 -3.4E38~3.4E38
double(双精度型) 8 -1.7E308~1.7E308
long(长整型) 8 -9223372036854775808 ~ 9223372036854775807
19. Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
大神又来了:https://blog.csdn.net/qq_27093465/article/details/52279473
21. Hash冲突怎么办?哪些解决散列冲突的方法?
Hash算法解决冲突的方法一般有以下几种常用的解决方法
1, 开放定址法:
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
公式为:fi(key) = (f(key)+di) MOD m (di=1,2,3,……,m-1)
※ 用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术在散列表中形成一个探测序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者
碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探测到开放的地址则表明表
中无待查的关键字,即查找失败。
比如说,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。 我们用散列函数f(key) = key mod l2
当计算前S个数{12,67,56,16,25}时,都是没有冲突的散列地址,直接存入:

计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。
于是我们应用上面的公式f(37) = (f(37)+1) mod 12 = 2。于是将37存入下标为2的位置:

2, 再哈希法:
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数
计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3, 链地址法:
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向
链表连接起来,如:
键值对k2, v2与键值对k1, v1通过计算后的索引值都为2,这时及产生冲突,但是可以通道next指针将k2, k1所在的节点连接起来,这样就解决了哈希的冲突问题
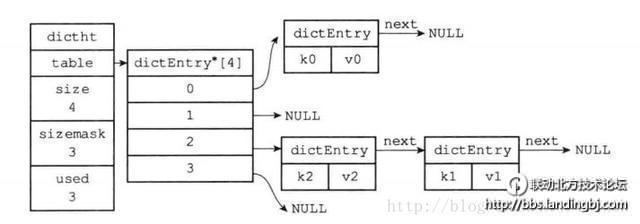
4, 建立公共溢出区:
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
22. hashCode() 与 equals() 生成算法、方法怎么重写
参考地址:https://blog.csdn.net/neosmith/article/details/17068365
结语
好了,今天的分享就到这里了,希望能够帮助到需要面试的道友顺利渡劫。高深的问题固然要好好回答,但基础也不能落下,顾此失彼导致薪资被砍相信也不是大家希望看到的,反正我是经历过,很难受,哈哈。
该贴被liuliying930406编辑于2018-10-9 18:13:51
 发起投票
发起投票









 加好友
加好友 发消息
发消息 2018-10-9 17:24:46 |
2018-10-9 17:24:46 |

 赞(
赞( 操作
操作
{kind=link}
{kind=link}