一.背景
缓存是我们在开发中为了提高系统的性能,把经常的访问业务的数据第一次把处理结果先放到缓存中,第二次就不用在对相同的业务数据在重新处理一遍,这样
就提高了系统的性能。缓存分好几种:
(1)本地缓存。
(2)数据库缓存。
(3)分布式缓存。
分布式缓存比较常用的有memcached等,memcached是高性能的分布式内存缓存服务器,缓存业务处理结果,减少数据库访问次数和相同复杂逻辑处理的时间,以
提高动态Web应用的速度、 提高可扩展性。
二.本地缓存在高并发下的问题以及解决
今天我们介绍的是本地缓存缓存,我们这边采用java.util.concurrent.ConcurrentHashMap来保存,ConcurrentHashMap是一个线程安全的HashTable,并提供了
一组和HashTable功能相同但是线程安全的方法,ConcurrentHashMap可以做到读取数据不加锁,提高了并发能力。我们先不考虑内存元素回收或者在保存数据会
出现内存溢出的情况,我们用ConcurrentHashMap模拟本地缓存,当在高并发环境一下,会出现一些什么问题?我们这边采用实现多个线程来模拟高并发场景。
第一种:我们先来看一下代码:
public class TestConcurrentHashMapCache<K,V> {
private final ConcurrentHashMap<K, V> cacheMap=new ConcurrentHashMap<K,V> ();
public Object getCache(K keyValue,String ThreadName){
System.out.println("ThreadName getCache=============="+ThreadName);
Object value=null;
//从缓存获取数据
value=cacheMap.get(keyValue);
//如果没有的话,把数据放到缓存
if(value==null){
return putCache(keyValue,ThreadName);
}
return value;
}
public Object putCache(K keyValue,String ThreadName){
System.out.println("ThreadName 执行业务数据并返回处理结果的数据(访问数据库等)=============="+ThreadName);
//可以根据业务从数据库获取等取得数据,这边就模拟已经获取数据了
@SuppressWarnings("unchecked")
V value=(V) "dataValue";
//把数据放到缓存
cacheMap.put(keyValue, value);
return value;
}
public static void main(String[] args) {
final TestConcurrentHashMapCache<String,String> TestGuaVA=new TestConcurrentHashMapCache<String,String>();
Thread t1=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T1======start========");
Object value=TestGuaVA.getCache("key","T1");
System.out.println("T1 value=============="+value);
System.out.println("T1======end========");
}
});
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T2======start========");
Object value=TestGuaVA.getCache("key","T2");
System.out.println("T2 value=============="+value);
System.out.println("T2======end========");
}
});
Thread t3=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T3======start========");
Object value=TestGuaVA.getCache("key","T3");
System.out.println("T3 value=============="+value);
System.out.println("T3======end========");
}
});
t1.start();
t2.start();
t3.start();
}
}我们看一下执行结果,如图所示:
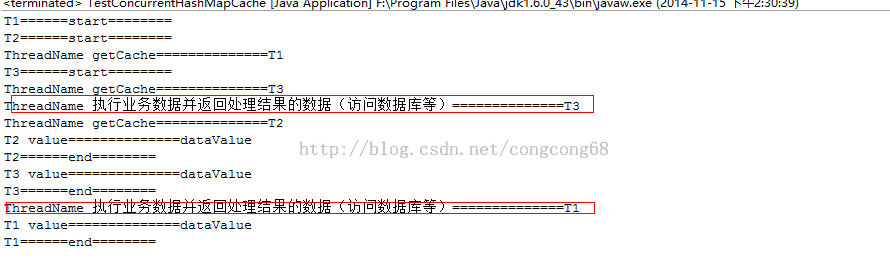
我们实现了本地缓存代码,我们执行一下结果,发现在多线程时,出现了在缓存里没有缓存时,会执行一样执行多次的业务数据并返回处理的数据,我们分析一
下出现这种情况的:
(1)当线程T1访问cacheMap里面有没有,这时根据业务到后台处理业务数据并返回处理数据,并放入缓存。
(2)当线程T2访问cacheMap里面同样也没有,也把根据业务到后台处理业务数据并返回处理数据,并放入缓存。
第二种:这样相同的业务并处理两遍,如果在高并发的情况下相同的业务不止执行两遍,这样这样跟我们当初做缓存不相符合,这时我们想到了Java多线程时,
在执行获取缓存上加上Synchronized,代码如下:
public class TestConcurrentHashMapCache<K,V> {
private final ConcurrentHashMap<K, V> cacheMap=new ConcurrentHashMap<K,V> ();
public <span style="color:#ff0000;">synchronized </span>Object getCache(K keyValue,String ThreadName){
System.out.println("ThreadName getCache=============="+ThreadName);
Object value=null;
//从缓存获取数据
value=cacheMap.get(keyValue);
//如果没有的话,把数据放到缓存
if(value==null){
return putCache(keyValue,ThreadName);
}
return value;
}
public Object putCache(K keyValue,String ThreadName){
System.out.println("ThreadName 执行业务数据并返回处理结果的数据(访问数据库等)=============="+ThreadName);
//可以根据业务从数据库获取等取得数据,这边就模拟已经获取数据了
@SuppressWarnings("unchecked")
V value=(V) "dataValue";
//把数据放到缓存
cacheMap.put(keyValue, value);
return value;
}
public static void main(String[] args) {
final TestConcurrentHashMapCache<String,String> TestGuaVA=new TestConcurrentHashMapCache<String,String>();
Thread t1=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T1======start========");
Object value=TestGuaVA.getCache("key","T1");
System.out.println("T1 value=============="+value);
System.out.println("T1======end========");
}
});
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T2======start========");
Object value=TestGuaVA.getCache("key","T2");
System.out.println("T2 value=============="+value);
System.out.println("T2======end========");
}
});
Thread t3=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T3======start========");
Object value=TestGuaVA.getCache("key","T3");
System.out.println("T3 value=============="+value);
System.out.println("T3======end========");
}
});
t1.start();
t2.start();
t3.start();
}
}执行结果,如图所示:

这样就实现了串行,在高并发行时,就不会出现了第二个访问相同业务,肯定是从缓存获取,但是加上Synchronized变成串行,这样在高并发行时性能也下降。
第三种:我们为了实现性能和缓存的结果,我们采用Future,因为Future在计算完成时获取,否则会一直阻塞直到任务转入完成状态和
ConcurrentHashMap.putIfAbsent方法,代码如下:
public class TestFutureCahe<K,V> {
private final ConcurrentHashMap<K, Future<V>> cacheMap=new ConcurrentHashMap<K, Future<V>> ();
public Object getCache(K keyValue,String ThreadName){
Future<V> value=null;
try{
System.out.println("ThreadName getCache=============="+ThreadName);
//从缓存获取数据
value=cacheMap.get(keyValue);
//如果没有的话,把数据放到缓存
if(value==null){
value= putCache(keyValue,ThreadName);
return value.get();
}
return value.get();
}catch (Exception e) {
}
return null;
}
public Future<V> putCache(K keyValue,final String ThreadName){
// //把数据放到缓存
Future<V> value=null;
Callable<V> callable=new Callable<V>() {
@SuppressWarnings("unchecked")
@Override
public V call() throws Exception {
//可以根据业务从数据库获取等取得数据,这边就模拟已经获取数据了
System.out.println("ThreadName 执行业务数据并返回处理结果的数据(访问数据库等)=============="+ThreadName);
return (V) "dataValue";
}
};
FutureTask<V> futureTask=new FutureTask<V>(callable);
value=cacheMap.putIfAbsent(keyValue, futureTask);
if(value==null){
value=futureTask;
futureTask.run();
}
return value;
}
public static void main(String[] args) {
final TestFutureCahe<String,String> TestGuaVA=new TestFutureCahe<String,String>();
Thread t1=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T1======start========");
Object value=TestGuaVA.getCache("key","T1");
System.out.println("T1 value=============="+value);
System.out.println("T1======end========");
}
});
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T2======start========");
Object value=TestGuaVA.getCache("key","T2");
System.out.println("T2 value=============="+value);
System.out.println("T2======end========");
}
});
Thread t3=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T3======start========");
Object value=TestGuaVA.getCache("key","T3");
System.out.println("T3 value=============="+value);
System.out.println("T3======end========");
}
});
t1.start();
t2.start();
t3.start();
}
}
线程T1或者线程T2访问cacheMap,如果都没有时,这时执行了FutureTask来完成异步任务,假如线程T1执行了FutureTask,并把保存到ConcurrentHashMap中,
通过PutIfAbsent方法,因为putIfAbsent方法如果不存在key对应的值,则将value以key加入Map,否则返回key对应的旧值。这时线程T2进来时可以获取Future
对象,如果没值没关系,这时是对象的引用,等FutureTask执行完,在通过get返回。
我们问题解决了高并发访问缓存的问题,可以回收元素这些,都没有,容易造成内存溢出,Google Guava Cache在这些问题方面都做得挺好的,接下来我们介
绍一下。
三.Google Guava Cache的介绍和应用
Guava Cache与ConcurrentMap很相似,Guava Cache能设置回收,能解决在大数据内存溢出的问题,源代码如下:
public class TestGuaVA<K,V> {
private Cache<K, V> cache= CacheBuilder.newBuilder() .maximumSize(2).expireAfterWrite(10, TimeUnit.MINUTES).build();
public Object getCache(K keyValue,final String ThreadName){
Object value=null;
try {
System.out.println("ThreadName getCache=============="+ThreadName);
//从缓存获取数据
value = cache.get(keyValue, new Callable<V>() {
@SuppressWarnings("unchecked")
public V call() {
System.out.println("ThreadName 执行业务数据并返回处理结果的数据(访问数据库等)=============="+ThreadName);
return (V) "dataValue";
}
});
} catch (ExecutionException e) {
e.printStackTrace();
}
return value;
}public static void main(String[] args) {
final TestGuaVA<String,String> TestGuaVA=new TestGuaVA<String,String>();
Thread t1=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T1======start========");
Object value=TestGuaVA.getCache("key","T1");
System.out.println("T1 value=============="+value);
System.out.println("T1======end========");}});
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T2======start========");
Object value=TestGuaVA.getCache("key","T2");
System.out.println("T2 value=============="+value);
System.out.println("T2======end========");
}
});
Thread t3=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("T3======start========");
Object value=TestGuaVA.getCache("key","T3");
System.out.println("T3 value=============="+value);
System.out.println("T3======end========");
}
});
t1.start();
t2.start();
t3.start();
}
}说明:
CacheBuilder.newBuilder()后面能带一些设置回收的方法:
(1)maximumSize(long):设置容量大小,超过就开始回收。
(2)expireAfterAccess(long, TimeUnit):在这个时间段内没有被读/写访问,就会被回收。
(3)expireAfterWrite(long, TimeUnit):在这个时间段内没有被写访问,就会被回收 。
(4)removalListener(RemovalListener):监听事件,在元素被删除时,进行监听。
执行结果,如图所示:

--转自

 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-12-11 15:06:13 |
2015-12-11 15:06:13 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}