要了解为什么会出现乱码,我们就先要理解:从客户端发起请求,到MySQL存储数据,再到下次从表取回客户端的过程中,哪些环节会有编码/解码的行为。为了更好的解释这个过程,博主制作了两张流程图,分别对应存入和取出两个阶段。
存入MySQL经历的编码转换过程
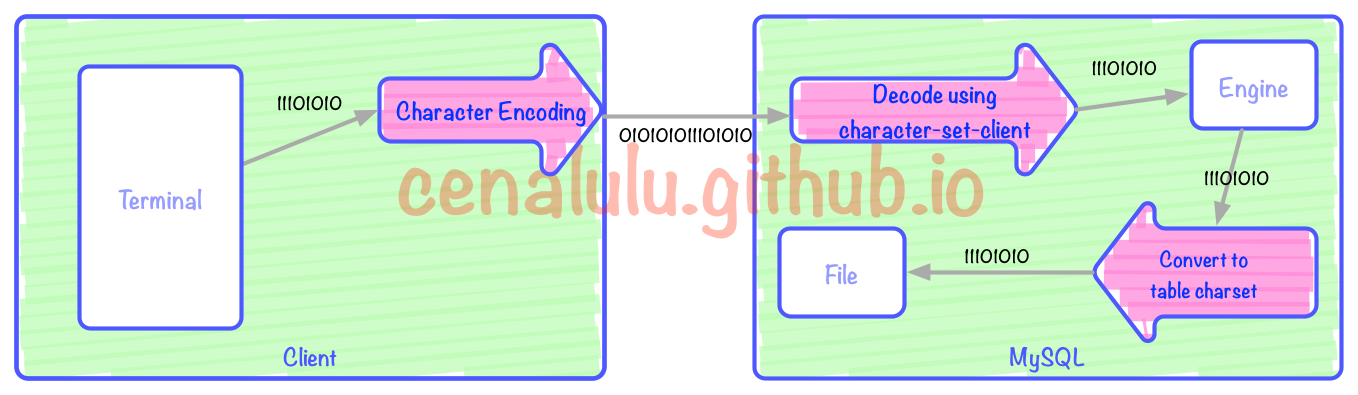
上图中有3次编码/解码的过程(红色箭头)。三个红色箭头分别对应:客户端编码,MySQL Server解码,Client编码向表编码的转换。其中Terminal可以是一个Bash,一个web页面又或者是一个APP。本文中我们假定Bash是我们的Terminal,即用户端的输入和展示界面。图中每一个框格对应的行为如下:
在terminal中使用输入法输入
terminal根据字符编码转换成二进制流
二进制流通过MySQL客户端传输到MySQL Server
Server通过character-set-client解码
判断character-set-client和目标表的charset是否一致
如果不一致则进行一次从client-charset到table-charset的一次字符编码转换
将转换后的字符编码二进制流存入文件中
从MySQL表中取出数据经历的编码转换过程
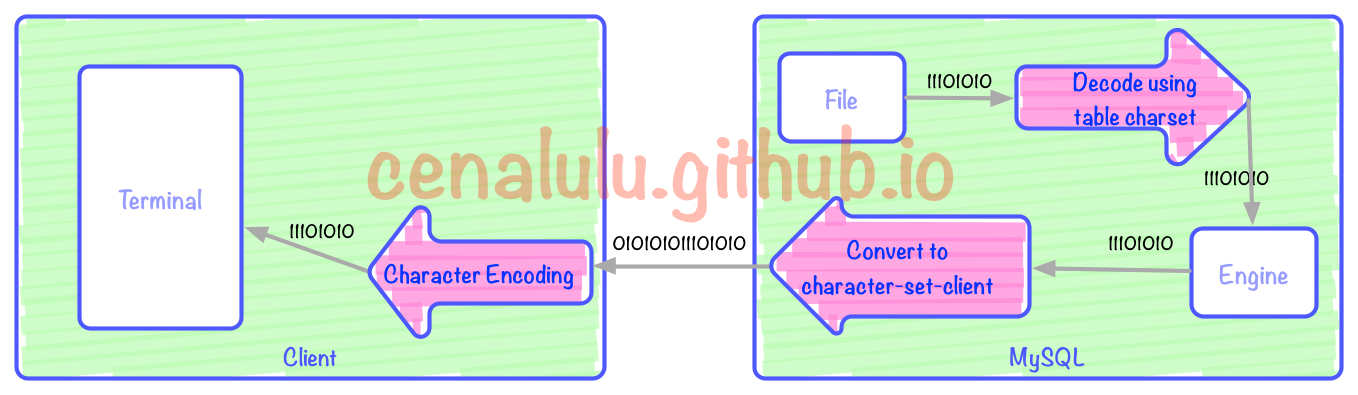
上图有3次编码/解码的过程(红色箭头)。上图中三个红色箭头分别对应:客户端解码展示,MySQL Server根据character-set-client编码,表编码向character-set-client编码的转换。
从文件读出二进制数据流
用表字符集编码进行解码
将数据转换为character-set-client的编码
使用character-set-client编码为二进制流
Server通过网络传输到远端client
client通过bash配置的字符编码展示查询结果
造成MySQL乱码的原因
1. 存入和取出时对应环节的编码不一致
这个会造成乱码是显而易见的。我们把存入阶段的三次编解码使用的字符集编号为C1,C2,C3(图一从左到右);取出时的三个字符集依次编号为C1’,C2’,C3’(从左到右)。那么存入的时候bash C1用的是UTF-8编码,取出的时候,C1'我们却使用了windows终端(默认是GBK编码),那么结果几乎一定是乱码。又或者存入MySQL的时候set names utf8(C2),而取出的时候却使用了set names gbk(C2'),那么结果也必然是乱码
2. 单个流程中三步的编码不一致
即上面任意一幅图中的同方向的三步中,只要两步或者两部以上的编码有不一致就有可能出现编解码错误。如果差异的两个字符集之间无法进行无损编码转换(下文会详细介绍),那么就一定会出现乱码。例如:我们的shell是UTF8编码,MySQL的character-set-client配置成了GBK,而表结构却又是charset=utf8,那么毫无疑问的一定会出现乱码。
这里我们就简单演示下这种情况

关于MySQL的编/解码
既然系统之间是按照二进制流进行传输的,那直接把这串二进制流直接存入表文件就好啦。为什么在存储之前还要进行两次编解码的操作呢?
Client to Server的编解码的原因是MySQL需要对传来的二进制流做语法和词法解析。如果不做编码解析和校验,我们甚至没法知道传来的一串二进制流是insert还是update。
File to Engine的编解码是为知道二进制流内的分词情况。举个简单的例子:我们想要从表里取出某个字段的前两个字符,执行了一句形如select left(col,2) from table的语句,存储引擎从文件读入该column的值是E4B8ADE69687。那么这个时候如果我们按照GBK把这个值分割成E4B8,ADE6,9687三个字,并那么返回客户端的值就应该是E4B8ADE6;如果按照UTF8分割成E4B8AD,E69687,那么就应该返回E4B8ADE69687两个字。可见,如果在从数据文件读入数据后,不进行编解码的话在存储引擎内部是无法进行字符级别的操作的。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-8-27 9:37:39 |
2015-8-27 9:37:39 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}