数据依赖路由DDR
什么是数据依赖路由(Data-Dependent Routing)
个人理解,DDR机制就是在处理客户端请求时,能够根据请求数据中的值(Field1=Value1)的不同(范围段)将请求分发到不同的组进行处理。大体上如下图所示。
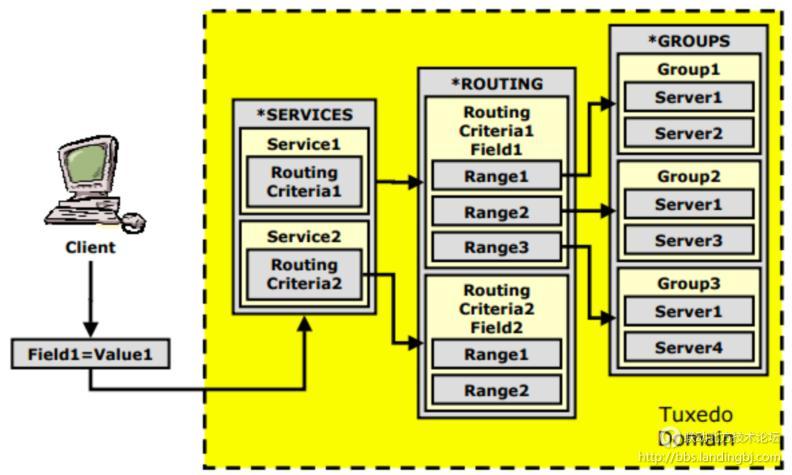
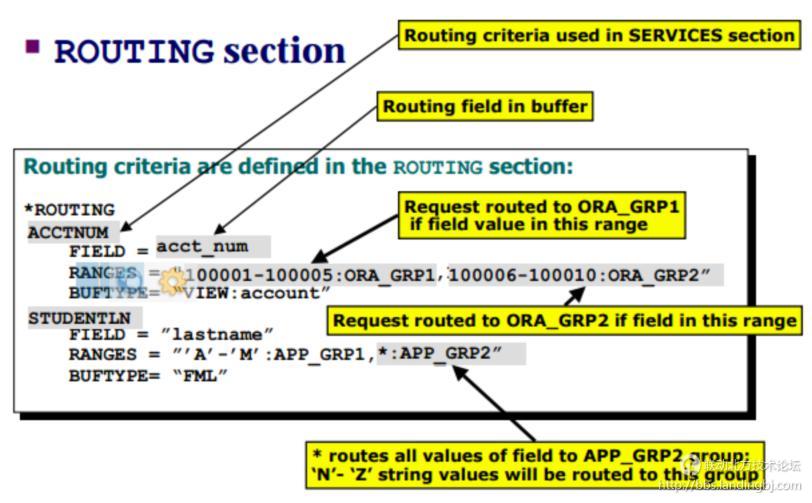
下面看看DDR该如何通过配置来实现,核心的路由规则在*ROUTING节下配置,其配置语法如下所示:

具体配置时,主要配置criterion_name(规则名称:在*SERVICES节引用)、FIELD(缓存中的字段名)、RANGS(范围:用来路由,好比数据库中根据分区字段的值不同划分不同的分区)、BUFTYPE(缓存类型:TUXEDO具体的缓存方式,后续跟帖说明),如下配置示例:
配好了路由规则,Services在处理请求时,同样也需要知道该用什么样的路由规则,这一步的配置很简单,直接在*SERVICES节下的SERVICE指定ROUTING参数,值就是上一步配置的路由规则名称。
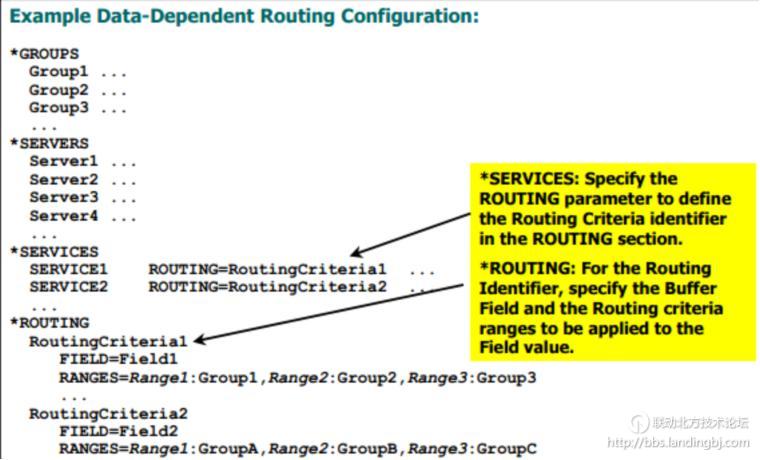
下面,我们再看看具体业务场景下,DDR的作用:
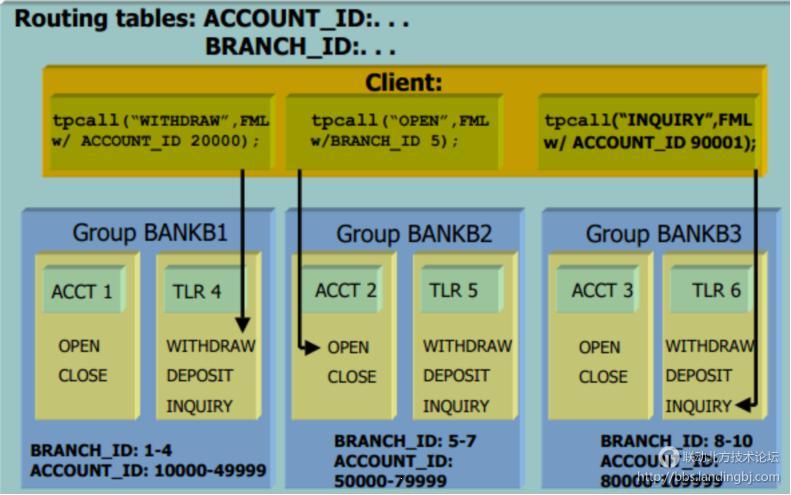
可以看到,上图定义了2套路由规则:一是根据BRANCH_ID进行路由;一是根据ACCOUNT_ID路由。分别路由到三组Group BANKB下,组下面下挂ACCT与TLR两套Servics,实现了针对账号或者组织结构的不同分别处理。现在反过来思考下,为什么要这么做呢?个人认为,原因可能在于两点:1)数据隔离;2)服务隔离。第一点是数据本身是分割在不同的数据库上,导致服务上须路由;第二点在于需要针对具体请求实现不同的处理方式,比如VIP与普通用户的处理流程、响应优先级、负载可能都有差异,通过DDR实现服务处理的隔离。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-7-29 15:29:06 |
2015-7-29 15:29:06 |
 赞(
赞( 操作
操作



{kind=link}
{kind=link}