对于查阅到的档案内容,一般上我们需要过滤掉无用的信息,从其中提取出我们需要的部分。常用命令有:
grep 用来查询满足指定条件的数据
sed 主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等
awk 主要是以列为单位进行处理
一、grep搜索文本
1.命令格式:
grep [选项] 模式 [文件...]
2.命令功能:
搜索文本的匹配内容,逐行搜索所指定的文件或标准输入,并显示匹配模式的每一行。
3.命令参数:
-b显示块号
-c仅显示各指定文件中包含模式的总行数
-i模式中字母不区分大小写
-h不将包含模式的文件名显示在该行上
-l仅显示包含模式的文件名
-n显示模式所在行的行号
-s指定文件若不存在或不可读,不提示错误信息
-v显示所有不包含模式的行
-w 精确查找
正规表达式可以是:
. 匹配任意一个字符
*匹配0个或多个*前的字符
^匹配行开头
$匹配行结尾
[]匹配[ ]中的任意一个字符,[]中可用 - 表示范围,
例如[a-z]表示字母a 至z 中的任意一个
\转意字符
4. 使用实例:
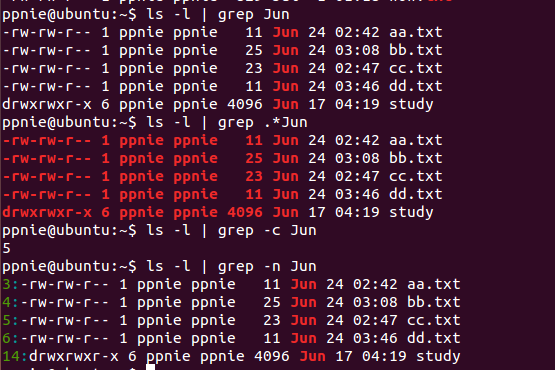
实例1:ls -l grep Jun 匹配所有有Jun 的行
ls -l grep .*Jun 匹配在Jun之前有任意字符的行
ls -l grep -c Jun 统计满足条件的总行数
ls -l grep -n Jun 在匹配行前输出其在档案中的行数
输出:
实例2:
grep -c “^$” aa.txt #统计aa.txt中的空行总数
grep “\$” aa.txt # 显示包含$ 字符的行,
grep -i “jun” aa.txt #忽视大小写,查找包含jun的行
ls -l grep -v Jun #显示不匹配模式的行
ls -l grep -E “Jun Jul” #显示匹配Jun或Jul模式的行
二、sed 对行匹配
1.命令格式:
sed [选项] 命令 [文件...]
2.命令功能:
主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作
3.命令参数:
-n∶使用安静(silent)模式,显示经过sed 特殊处理的那一行(或者动作)
-i∶直接修改读取的档案内容,而不是由萤幕输出。
-e: 多个匹配
常用命令:
= 显示文件行号
a 在定位行号后附加新文本信息,附加
d 删除定位行,删除
g 全局替换
i 在定位行号后插入新文本信息,插入
p 打印匹配行
q 第一个模式匹配完成后推出或立即推出
r 从另一个文件中读文本
s 使用替换模式替换相应模式
w 写文本到一个文件
4. 使用实例:
实例1:
sed -n '2p' quote.txt #只打印第二行
sed -n '1,3p' quote.txt #打印1-3行
sed -n '3,$p' quote.txt #打印3到最后一行,$为最后一行的意思
sed -n '/Neave/'p quote.txt #打印匹配单词Neave的行
sed -n '/\$/'p quote.txt #查询包含$的行,特殊字符前需要使用转义字符'\' 屏蔽其特殊含义
sed -e '/music/=' quote.txt #打印所有内容,并在匹配行前一行打印行号。
sed -n '/music/=' quote.txt #只打印匹配行号。= 显示出行号
sed -n -e '/music/p' -e '/music/=' quote.txt #打印匹配行和行号
sed '1,$d' quote.txt #删除1到最后一行,原始文件不变,只是显示在屏幕上的字符没有这些行而已
sed '/company/d' quote.txt #匹配删除
sed 's/night/NIGHT/' quote.txt #用NIGHT替换第一个匹配的night
sed 's/night/NIGHT/g' quote.txt #用NIGHT替换全部匹配的night
sed 's/\$//' quote.txt #将字符$删除,因为没有用任何字符来替换
sed -n 's/nurse/"Hello" &/p' quote.txt #修改模式后带 &,将其放在匹配模式之前
sed 's/[0-9][0-9]*/& Passed/g' une.txt #修改模式前带&,将其放在匹配模式之后, 可以理解为& 是为匹配模式占位
sed '1,2 w send.out' quote.txt #将1,2行内容写入send.out,w写
sed '/good/ w send.out' quote.txt #将匹配行内容写入send.out
sed '/.a.*/q' quote.txt #查询模式首次出现行,并退出
sed -i '/world/s/jint/jjjjjjj/g' test.sh
cat dos.txt sed 's/^0*//g' sed 's/^M//g' sed 's/##//g'
#将dos.txt文件,删除行首的任意个0,删除控制字符,并用空格替换##
三、awk 对列匹配
1.命令格式:
awk [-F field-separator] 'commands' input-file(s)
2.命令功能:
能够依照用户定义的格式来分解输入的资料也可以依照用户定义的格式来打印资料。
3.命令参数:
-F 指定列分割符,默认用空格为分割符
$0 打印整行
$NF 打印每行的最后一个字段,$(NF-1) 倒数第二个字段
NR 打印行号
4. 使用实例:
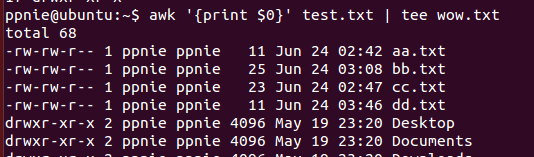
实例1:在屏幕上输出test.txt的全部列,并将其写入wow文件中
命令:awk '{print $0}' test.txt tee wow.txt
输出:
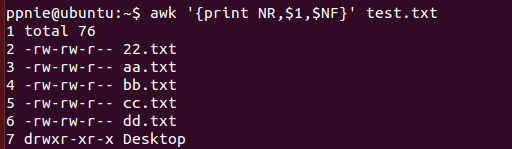
实例2:在屏幕上输出test.txt的行号,第一列和最后一列
命令:awk '{print NR,$1,$NF}' test.txt
输出:
实例3:
awk 'BEGIN{print"Name\n---------"}{print $1}END{print "end-of reports"}' une.txt #在屏幕上加入报告头,和信息尾
awk '{if($4~/good/)print $1}' grade.txt #将第四列与good匹配,打印匹配行的第一列
awk '$3=="48" {print $0}' grade.txt #精确匹配,只能是48
awk '{if($3~/48/) print $0}' grade.txt #模糊匹配,第三列有48即可
awk 'END {print NR}' grade.txt #查看整个记录的总行数
awk '{print NF,NR,$0}END{print FILENAME}' grade.txt #NF记录的总列数,NR 行数,$0 全部列,并在结尾处添上 文件名
 发起投票
发起投票

 技术讨论
技术讨论






 加好友
加好友 发消息
发消息 2015-7-1 17:27:06 |
2015-7-1 17:27:06 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}