使用explain查看,如下
1、首先创建表test,语句如下
[sql]view plaincopy
createtable test(a int,b varchar(10),c varchar(10));
2、在表中的a,b都创建索引,先后顺序是a,b
[sql]view plaincopy
createindex idx_a_b on test(a,b);
3、分别往里面插入三条数据,插入后结果如下:
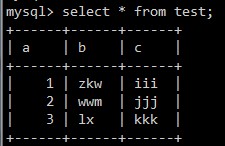
4、使用explain查询,查看索引使用情况(这里还可以进行多次其他sql语句的查询,查看索引利用情况)

从上面可以看到key_len使用的长度为38(字节),那么总的索引长度是多少呢?
下面继续对表的创建进行查看,查看各个字段的大小
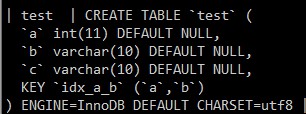
其中:
latin1 = 1 byte = 1 character
uft8 = 3 byte = 1 character
gbk = 2 byte = 1 character
从上面这些可以计算索引的长度:
10*3(varchar 10)+3(标记变长)+1(标记可为null)+其他(不清楚)
组合索引的长度10*3+11已经大于38,所以推论只用到了组合索引的一部分。
5、下面是对explain其他的参数进行说明:
table:
这是表的名字。type:
连接操作的类型。
下面是MySQL文档关于ref连接类型的说明:
“对于每一种与另一个表中记录的组合,MySQL将从当前的表读取所有带有匹配索引值的记录。如果连接操作只使用键的最左前缀,或者如果键不是UNIQUE或PRIMARY KEY类型(换句话说,如果连接操作不能根据键值选择出唯一行),则MySQL使用ref连接类型。如果连接操作所用的键只匹配少量的记录,则ref是一种好的连接类型。”
在本例中,由于索引不是UNIQUE类型,ref是我们能够得到的最好连接类型。
如果EXPLAIN显示连接类型是“ALL”,而且你并不想从表里面选择出大多数记录,那么MySQL的操作效率将非常低,因为它要扫描整个表。你可以加入更多的索引来解决这个问题。本例子中是rang,下面是对type值的解释
Type:告诉我们对表所使用的访问方式,主要包含如下集中类型;
◇ all:全表扫描
◇ const:读常量,且最多只会有一条记录匹配,由于是常量,所以实际上只需要读一次;
◇ eq_ref:最多只会有一条匹配结果,一般是通过主键或者唯一键索引来访问;
◇ fulltext:
◇ index:全索引扫描;
◇ index_merge:查询中同时使用两个(或更多)索引,然后对索引结果进行merge 之后再读
取表数据;
◇ index_subquery:子查询中的返回结果字段组合是一个索引(或索引组合),但不是一个
主键或者唯一索引;
◇ rang:索引范围扫描;
◇ ref:Join 语句中被驱动表索引引用查询;
◇ ref_or_null:与ref 的唯一区别就是在使用索引引用查询之外再增加一个空值的查询;
◇ system:系统表,表中只有一行数据;
◇ unique_subquery:子查询中的返回结果字段组合是主键或者唯一约束;
possible_keys:
可能可以利用的索引的名字。这里的索引名字是创建索引时指定的索引昵称;如果索引没有昵称,则默认显示的是索引中第一个列的名字(在本例中,它是“firstname”)。默认索引名字的含义往往不是很明显。
key:
它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
key_len:
索引中被使用部分的长度,以字节计ref:
列出是通过常量(const),还是某个表的某个字段(如果是join)来过滤(通过key)
的;
rows:
MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1。
--转自

 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-6-9 10:35:31 |
2015-6-9 10:35:31 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}