1、并行数据库
1.1、并行数据库的体系结构
并行机的出现,催生了并行数据库的出现,不对,应该是关系运算本来就是高度可并行的。对数据库系统性能的度量主要有两种方式:(1)吞吐量(Throughput),在给定的时间段里所能完成的任务数量;(2)响应时间(Response time),单个任务从提交到完成所需要的时间。对于处理大量小事务的系统,通过并行地处理许多事务可以提高它的吞吐量。对于处理大事务的系统,通过并行的执行事务的子任务,可以缩短系统晌应时间。
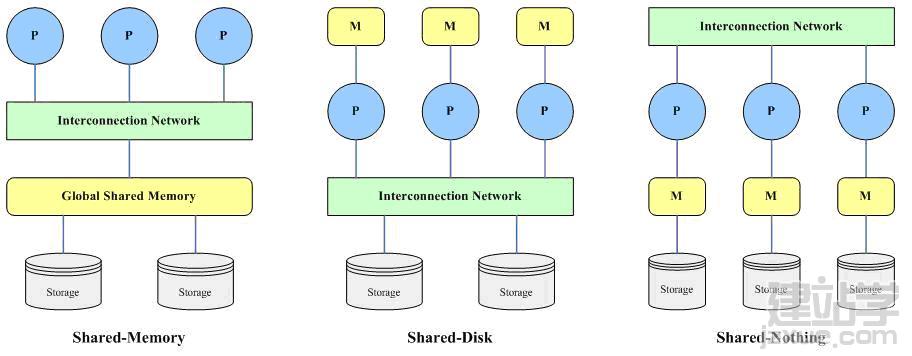
并行机有三种基本的体系结构,相应的,并行数据库的体系结构也可以大概分为三类:
共享内存(share memeory):所有处理器共享一个公共的存储器;
共享磁盘(share disk):所有处理器共享公共的磁盘;这种结构有时又叫做集群(cluster);
无共享(share nothing):所有处理器既不共享内存,也不共享磁盘。
如图所示:
1.1.1、 共享内存
该结构包括多个处理器、一个全局共享的内存(主存储器)和多个磁盘存储,各个处理器通过高速通讯网络(Interconnection Network)与共享内存连接,并均可直接访问系统中的一个、多个或全部的磁盘存储,在系统中,所有的内存和磁盘存储均由多个处理器共享。
这种结构的优点在于,处理器之间的通信效率极高,访问内存的速度要比消息通信机制要快很多。这种结构的缺点在于,处理器的规模不能超过32个或者64个,因为总线或互边网络是由所有的处理器共享,它会变成瓶颈。当处理器数量到达某一个点时,再增加处理器已经没有什么好处。
共享内存结构通常在每个处理器上有很大的高速缓存,从而减少对内存的访问。但是,这些高速缓存必须保持一致,也就是缓存一致性(cache-coherency)的问题。
1.1.2、 共享磁盘
该结构由多个具有独立内存(主存储器)的处理器和多个磁盘存储构成,各个处理器相互之间没有任何直接的信息和数据的交换,多个处理器和磁盘存储由高速通信网络连接,每个处理器都可以读写全部的磁盘存储。
共享磁盘与共享内存结构相比,有以下一些优点:(1)每个处理器都有自己的存储器,存储总线不再是瓶颈;(2)以一种较经济的方式提供了容错性(fault tolerence),如果一个处器发生故障,其它处理器可以代替工作。
该结构的主要问题不是在于可扩展性问题,虽然存储总线不是瓶颈,但是,与磁盘之间的连接又成了瓶颈。
运行Rdb的DEC集群是共享磁盘的体系结构的早期商用化产品之一(DEC后来被Compaq公司收购,再后来,Oracle又从Compaq手中取得Rdb,发展成现在的Oracle RAC)。
1.1.3、 无共享
该结构由多个完全独立的处理节点构成,每个处理节点具有自己独立的处理器、独立的内存(主存储器)和独立的磁盘存储,多个处理节点在处理器级由高速通信网络连接,系统中的各个处理器使用自己的内存独立地处理自己的数据。
这 种结构中,每一个处理节点就是一个小型的数据库系统,多个节点一起构成整个的分布式的并行数据库系统。由于每个处理器使用自己的资源处理自己的数据,不存 在内存和磁盘的争用,提高的整体性能。另外这种结构具有优良的可扩展性——只需增加额外的处理节点,就可以以接近线性的比例增加系统的处理能力。
这种结构中,由于数据是各个处理器私有的,因此系统中数据的分布就需要特殊的处理,以尽量保证系统中各个节点的负载基本平衡,但在目前的数据库领域,这个数据分布问题已经有比较合理的解决方案。
由于数据是分布在各个处理节点上的,因此,使用这种结构的并行数据库系统,在扩展时不可避免地会导致数据在整个系统范围内的重分布(Re-Distribution)问题。
Shared-Nothing结构的典型代表是Teradata(并行数据库的先驱),值得一提的是,MySQL NDB Cluster也使用了这种结构。
1.2、I/O并行(I/O Parallelism)
I/O并行的最简单形式是通过对关系划分,放置到多个磁盘上来缩减从磁盘读取关系的时间。并行数据库中数据划分最通用的形式是水平划分(horizontal portioning),一个关系中的元组被划分到多个磁盘。
1.2.1、常用划分技术
假定将数据划分到n个磁盘D0,D1,…,Dn中。
(1) 轮转法(round-bin)。对关系顺序扫描,将第i个元组存储到标号为Di%n的磁盘上;该方式保证了元组在多个磁盘上均匀分布。
(2) 散列划分(hash partion)。选定一个值域为{0, 1, …,n-1}的散列函数,对关系中的元组基于划分属性进行散列。如果散列函数返回i,则将其存储到第i个磁盘。
(3) 范围划分(range partion)。
由于将关系存储到多个磁盘,读写时能同时进行,划分(partion)能大大提高系统的读写性能。数据的存取可以分为以下几类:
(1) 扫描整个关系;
(2) 点查询(point query),如name = “hustcat”;
(3) 范围查询(range query),如 20 < age < 30。
不同的划分技术,对这些存取类型的效率是不同的:
轮转法适合顺序扫描关系,对点查询和范围查询的处理较复杂。
散列划分特别适合点查询,速度最快。
范围划分对点查询、范围查询以及顺序扫描都支持较好,所以适用性很广。但是,这种方式存在一个问题——执行偏斜(execution skew),也就是说某些范围的元组较多,使得大量的I/O出现在某几个磁盘。
--转自

 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2014-12-19 14:55:33 |
2014-12-19 14:55:33 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}