从0.23.0开始,Hadoop开始支持分布式NameNode,通过NameNode federation的形式实现。这样实现了NameNode的横向扩展,使得Hadoop集群的规模可以达到上万台。同时在NameNode HA机制方面,trunk中的代码也开始merge进ha-branch的功能,原来的SecondaryNamenode被BackupNode和CheckpointNode替代。本文主要讨论NameNode federation。
1,分布式NameNode基本原理和设计
HDFS存储包括两层:
(1) Namespace 管理directory, file and block,支持文件系统操作(也就是client端的文件系统操作,如create,delete,read,write等首先与Namespace打交道)。
(2) Block Storage主要由两部分组成:Block Management负责维护集群中NameNode与众多DataNode的关系以及create chunk,delete chunk等数据块操作;Physical Storage负责chunk的存储。

上面这张图可以清晰的看出,Block Storage的两部分功能分别在NameNode和DataNode中完成。在原来的单NameNode架构中,一个NameNode对应一个Namespace,对应多个DataNode组成的存储池空间,实现和理解起来非常容易。但是随着单NameNode遇到越来越多的问题,例如随着集群规模的扩大NameNode的内存已不能容纳所有的元数据;单NameNode制约文件元数据操作的吞吐量使得目前的只能支持60K的MapReduce task;还有就是不同用户的隔离性问题。
��� 那么社区为什么会选择NameNode federation这种方案呢?因为从系统设计的角度看,ceph的动态分区看起来更适合分布式NameNode的需求。这里就不得不说在系统领域学术界和工业界的区别了。Ceph的设计固然比较先进,但是稳定性非常不好。而对于一个像Hadoop这样规模的存储系统,稳定性固然非常重要,而且开发成本和兼容性也要考虑。NameNode federation这个方案对代码的改动大部分是在DataNode这块,对NameNode的改动很小。这使得NameNode的鲁棒性不会受到影响,同时也兼容原来的版本。
在工业界也有几种其他的分布式NameNode的实现方式,例如在百度内部使用的就是把NameNode做成一主多从的集群的形式,结构如下图所示。Namespace server负责整个集群的 文件ßà唯一的块集合ID 映射,然后把不同的 块集合ID分配到对应的FMS server上(类似于数据库里的sharding,可以采用hash类似的策略)。然后每个FMS server负责一部分块集合的管理和操作。那么这种方法显然client的每次文件操作都会经过Namespace server和其中的一个FMS server的处理。具体是怎么做的,百度也没开源出来。

另外就是MapR的实现方式(http://www.mapr.com/),用Hbase的方式(Google在GFS2中使用的策略,有开源POC实现http://code.google.com/p/hdfs-dnn/),用MySQL的方式(https://github.com/lalithsuresh/Scaling-HDFS-NameNode)等。
在NameNode federation中,每个NameNode节点是一个nameservice ,负责管理一个Namespace和对应的Block pool。整个集群有一个公共的ClusterID。在我的部署方案中,共有两个Namespace: ns1和ns2。所以对应有两个block pool。相应的Block pool ID可以在format文件系统之后获取,这个后面会讲到。同时在每个DataNode节点的dfs.datanode.dir目录下会为每个block pool分配以block pool ID命名的文件夹来存储对应block pool的块数据。

Federation中存在多个命名空间,如何划分和管理这些命名空间非常关键。例如查看某个目录下面的文件,如果采用文件名hash的方法存放文件,则这些文件可能被放到不同namespace中,HDFS需要访问所有namespace,代价过大。为了方便管理多个命名空间,HDFS NameNode Federation采用了经典的Client Side Mount Table。

如上图所示,下面四个蓝色三角形代表一个独立的Namespace,上方灰色的三角形代表从客户角度去访问的逻辑Namespace。各个蓝色的Namespace mount到灰色的表中,客户可以通过访问不同的挂载点来访问不同的namespace,这就如同在Linux系统中访问不同挂载点的磁盘一样。这就是HDFS NameNode Federation中命名空间管理的基本原理。但是这种方式容易造成不同Namespace下文件数量和存储量的不均衡,需要人工介入已达到理想的负载均衡。
HDFS NameNode Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件就不可以访问。所以对于其中的任何一个namenode依然存在SPOF问题,而这个问题的解决要依赖于HA的实现。就是给每个NameNode配备一个对应的BackupNode和CheckpointNode。
2, 编译源代码
注:如果你只关注怎么安装和使用,对Hadoop的源代码编译不是很感兴趣,可以直接从官网上download安装包,然后跳过这一节,直接进入第二节:安装与部署。
先从SVN中checkout代码,我checkout的是trunk中的代码。据说trunk中的代码merge了ha-branch,具体都merge了哪些jira讨论的东西没仔细看。
下图就是Checkout出的代码结构。这个和以前的版本源代码结构有很大的不同。整个项目采用maven作为项目管理工具。我对maven也是新手,不过BUILDING.txt会告诉我们大部分想要知道的东西。

Maven管理项目有很强的层次关系,在这里hadoop-project是Main Hadoop project,也是所有Hadoop Maven modules的parent POM。而hadoop-project-dist是用来生成分发模块的;hadoop-annotations是用来生成文档的;hadoop-common-project,hadoop-hdfs-project,hadoop-mapreduce-project这三个就是hadoop的主要三个功能模块;hadoop-tools是像Streaming, Distcp这样的工具。
具体到怎么编译source code,就按照BUILDING.txt里所说的。我简单说下我的环境:Ubuntu Linux, Java 1.7.0_02, protocolbuffer-2.4.1。这些准备工作都好了,就可以按照BUILDING.txt里��说的一样,敲一个mvn package -Pdist -DskipTests –Dtar,然后等大概15分钟左右(我的开发机是虚拟机,比较弱)就编译完了。
编译成功之后会在hadoop-dist目录下出现一个文件夹target,在这个文件夹里的内容如下:

其中的hadoop-3.0.0-SNAPSHOT.tar.gz就是我们部署时要用到的jar包和脚本的所在地了,和我们从hadoop.apache.org中download下来的安装包是基本一样的。例如,我们从官网上download下来的分发安装包hadoop-0.23.1.tar.gz,里面有:bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share。在我们自己编译出来的hadoop-3.0.0-SNAPSHOT.tar.gz解压出来也是这些东西。
至此,我们通过自己编译的方式,得到了和官网上download下来的安装包一样的东西。那么我们的第一阶段工作就结束了。
3,安装与部署。
大家可以使用第一节自己编译出来的安装包,或者从官网上download下来的安装包。0.23.0以后的版本在hadoop的安装包的文件布局发生了很大的变化。

从中可以看出,这个目录结构很像Linux操作系统的目录结构,是不是可以看出Hadoop希望自己成为在Big Data领域的操作系统啊。各个目录的作用如下:
(1)在新版本的hadoop中,由于使用hadoop的用户被分成了不同的用户组,就像Linux一样。因此执行文件和脚本被分成了两部分,分别存放在bin和sbin目录下。存放在sbin目录下的是只有超级用户(superuser)才有权限执行的脚本,比如start-dfs.sh, start-yarn.sh, stop-dfs.sh, stop-yarn.sh等,这些是对整个集群的操作,只有superuser才有权限。而存放在bin目录下的脚本所有的用户都有执行的权限,这里的脚本一般都是对集群中具体的文件或者block pool操作的命令,如上传文件,查看集群的使用情况等。
(2)etc目录下存放的就是在0.23.0版本以前conf目录下存放的东西,就是对common, hdfs, mapreduce(yarn)的配置信息。
(3)include和lib目录下,存放的是使用Hadoop的C语言接口开发用到的头文件和链接的库。
(4)libexec目录下存放的是hadoop的配置脚本,具体怎么用到的这些脚本,我也还没跟踪到。目前我就是在其中hadoop-config.sh文件中增加了JAVA_HOME环境变量。
(5)logs目录在download到的安装包里是没有的,如果你安装并运行了hadoop,就会生成logs 这个目录和里面的日志。
(6)share这个文件夹存放的是doc文档和最重要的Hadoop源代码编译生成的jar包文件,就是运行hadoop所用到的所有的jar包。
这样的目录结构是不是很清晰啊~
下一步就开始安装了。这次我主要测试和分析了NameNode federation这个feature,所以我的部署结构是这样的:
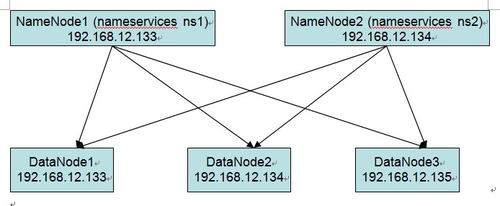
我一共有3台机器,133和134这两台作为我的NameNode,同时相应的SecondaryNamenode也放到这两台上(实际生产的集群中不应该这样使用,本文中只是做了功能测试,为了简便。而且在0.23.1后面的版本中SecondaryNamenode也是一个Deprecated的类,将会被BackupNode with -checkpoint argument所代替)。在133,134,135三台机器中部署DataNode。
部署步骤:
(1) 配置SSH无密码登录,注意所有的NameNode都要能够无密码登录到所有的DataNode中。
(2)配置环境变量,hadoop的那些执行脚本会用到。
在~/.bashrc文件内添加(注意,此处我们目前只配置了HDFS的环境变量,没有配置MapReduce/yarn的环境变量)
export HADOOP_DEV_HOME=/home/administrator/cloud/hadoop-0.23.1
export HADOOP_COMMON_HOME=$HADOOP_DEV_HOME
export HADOOP_HDFS_HOME=$HADOOP_DEV_HOME
export HADOOP_CONF_DIR=$HADOOP_DEV_HOME/etc/hadoop
(3)在libexec/hadoop-config.sh中添加JAVA_HOME ==/usr/lib/jvm/java-6-openjdk
(4)然后就是按照我们的部署方案,配置hadoop的参数了。我们前面已经提到了,在0.23.1之后的版本中,hadoop的配置文件都是放到了etc/hadoop/目录里,而且所��节点的配置文件都是统一的,省得还去区分NameNode和DataNode,配置一份然后拷贝到所有节点就行了。我们首先修改core-site.xml,添加hadoop.tmp.dir属性。由于在core-default.xml中,hadoop.tmp.dir被默认设置在/tmp目录下,重启机器数据就会丢失,所以我们必须覆盖这个配置项。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/administrator/cloud/tmp</value>
</property>
</configuration>
Hdfs-site.xml中的配置项:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/administrator/cloud/hdfs23</value>
</property>
<property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>192.168.12.133:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>192.168.12.133:23001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>192.168.12.133:23002</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>192.168.12.134:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>192.168.12.134:23001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>192.168.12.134:23002</value>
</property>
</configuration>
NameNode federation的配置其实是向后兼容的,你还可以像原来的方式一样把它配置成single namenode。对于我们想配置成NameNode federation的方式的话,引入了一些新的参数如下表所示:
Daemon Configuration Parameter
Namenode dfs.namenode.rpc-address
dfs.namenode.servicerpc-address
dfs.namenode.http-address
dfs.namenode.https-address
dfs.namenode.keytab.file
dfs.namenode.name.dir
dfs.namenode.edits.dir
dfs.namenode.checkpoint.dir
dfs.namenode.checkpoint.edits.dir
dfs.federation.nameservices
Secondary Namenode dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file
BackupNode dfs.namenode.backup.address dfs.secondary.namenode.keytab.file
就像我的部署实例中描述的那样,dfs.federation.nameservices表示两个NameServiceID,在我的例子中分别是ns1和ns2。然后分别配置这两个nameservice的rpc-address。这个dfs.namenode.rpc-address.是非常重要的属性,因为在后续对NameService的访问中都是通过这个属性的值来完成的。dfs.namenode.http-address是通过web浏览器访问监控信息的端口,也就是默认50070的那个端口。dfs.namenode.name.dir和dfs.namenode.edits.dir表示的是NameNode节点的Namespace元数据存放的本地目录,默认是在hadoop.tmp.dir目录下的某一位置,我们可以修改。
同时,这里面提到了两个RPC端口,分别是dfs.namenode.rpc-address和dfs.namenode.servicerpc-address。如果像我的例子中一样,只配置dfs.namenode.rpc-address,那么NameNode-Client和NameNode-DataNode之间的RPC都走的是这个端口。如果配置了后者与前者不同,那么dfs.namenode.rpc-address表示的是NameNode-Client之间的RPC,而dfs.namenode.servicerpc-address表示的是NameNode-DataNode之间的RPC。之所以要区别开来,我想主要是因为datanode和namenode通讯时不会影响client和namenode的通讯,因为同一个端口同时打开的句柄毕竟是预先设定的,缺省为10个。
(5)配置好了这些之后,就可以格式化文件系统了。由于我们部署了2个NameNode,所以我们需要在133和134两台机器上分别执行${HADOOP_DEV_HOME}/bin/hdfs namenode -format -clusterid eric命令。注意两台机器上指定的clusterid是一样的,表示这两个namenode组成的是同一个集群。
那么在执行了format之后,在192.168.12.133节点的dfs.namenode.name.dir目录下生成了current目录,在current目录里有个VERSION文件,内容如下:
#Thu Apr 19 11:29:05 CST 2012
namespaceID=2025563670
clusterID=eric
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1450194670-192.168.12.133-1334806145084
layoutVersion=-39
和以前的版本相比多了clusterID和blockpoolID这两项。clusterID就是我们刚才在format时指定的集群ID,在整个集群中是唯一的。而blockpoolID就是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-1450194670-192.168.12.133-1334806145084就是在我的ns1的namespace下的存储块池的ID,这个ID包括了其对应的NameNode节点的ip地址。
在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。

然后就可以通过执行sbin/start-dfs.sh启动整个HDFS集群了。
(6)FsShell使用
在使用过程中也有些不同,例如使用FsShell进行一些文件操作,例如原来的操作是:
Bin/hadoop fs –put /home/test /cloud/
那么现在要这样操作
Bin/hadoop fs –put /home/test hdfs://192.168.12.133:9000/cloud/
也就是说从FsShell中操作文件要指定HDFS的namespace,这也是我前面说的为什么dfs.namenode.rpc-address这个属性很重要的原因。
而且在0.23.1以后的版本中,像bin/hdfs dfsadmin –report这样的命令执行是需要配置fs.default.name这个参数的。也就是说很多hdfs的命令需要指定相应的namespace,然后这个shell的操作都是对这个namespace的操作。
当然大多数情况下还是利用client-api来进行hdfs的操作,从api的角度看,现在提供的接口除了DistributedFileSystem外,又提供了一个DFSAdmin接口,用于对文件系统的管理操作。hadoop在后续的版本中会发布hadoop-client这个工程模块,相信会把client的易用性有所提升。
(7)web监控界面

 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2013-6-28 10:57:42 |
2013-6-28 10:57:42 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}