根据网上相关帖子以及查看部分源代码,把作业提交流程画了个流程图,并对某些步骤做详细说明,现整理如下:
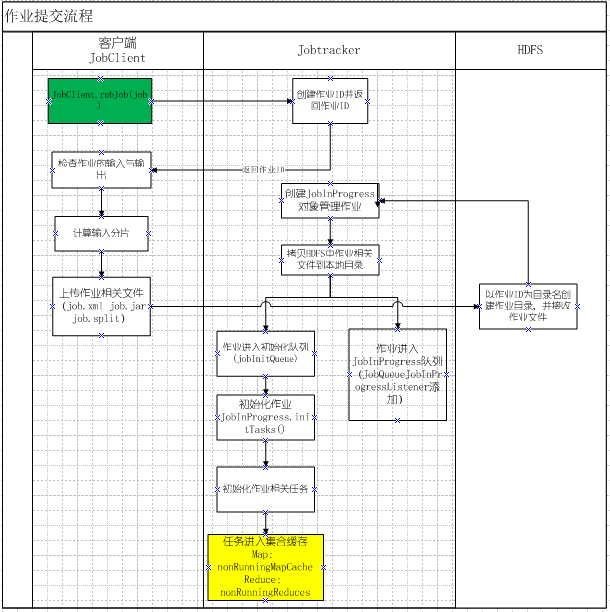
详细说明:
一 关于分片
1).分片的原则是:尽量保证一个片的数据不要跨数据节点,因此,最佳实践为片的大小与数据块的大小一致,这也是默认的策略
2).分片算法由FileInput接口定义,所有输入格式指定类都必须实现此接口;分片的信息写入文件job.split中,此文件的内容格式如下:
split文件头,split文件版本号,split的个数
//以下是每个分片的信息
split类型名(默认FileSplit),split的大小,split的内容(对于FileSplit,写入文件名,此split 在文件中的起始位置),split的location信息(即在那些DataNode上)
二.作业初始化
作业的初始化,主要工作就是初始化任务;
map任务:
1)通过JobClient的readSplitFile()获取分片信息
2)初始化队列监听器EagerTaskInitializationListener把作业(JobInProgress)加入初始化队列
public void jobAdded(JobInProgress job) {
synchronized (jobInitQueue) {
//加入初始化队列,这是一个List
jobInitQueue.add(job);
//根据作业优先级对作业进行排序
resortInitQueue();
//通知初始化线程JobInitThread进行初始化
jobInitQueue.notifyAll();
}
}
3)根据分片的数目创建同样多的map任务管理对象TaskInProgress
4)根据分片数据所在的数据节点位置,绑定任务,即把任务分配给数据所在的节点。但是,只是一个关系映射,并没有真正的传输任务
5)第四步中的这种映射关系存储在名叫nonRunningMapCache的map结构中,map的定义为:Map<Node, List<TaskInProgress>>
6.当某个节点有空闲的任务槽的时候,会通过心跳向jobTracker要任务,此时就可以根据自己的节点位置从nonRunningMapCache中获取任务
reduce任务:
其它跟map相似,只有一下几点不一样
1)reduce任务数由JobConf配置指定,通过方法setNumReduceTasks(int num)指定
2)reduce也有一个缓存集合存储reduce任务管理对象,但是它并不需要对节点进行分配,因为reduce任务的输入是map的输出,会有多个节点输出,所以不用刻意
补充说明:当作业准备好后,接下来就是作业的分配,作业的分配本质是作业任务的分配,其次,任务分配的过程是针对整个集群中处于运行状态的所有作业的分配,根据当前taskTracker节点在机架组织结构中的位置从近到远获取任务;
作业分配步骤:
1.taskTracker通过心跳向jobTracker获取任务
2.jobTracker检查上一个心跳响应是否完成
3.检查要启动的任务数是否超出心跳节点还剩余的任务槽,超出则不分配
4.检查即将启动的任务数和已经启动的任务数是否超过集群总的负载能力,如果超出则不分配,不超出则往下执行
5.获取任务时,是从当前集群中所有正��运行的作业的所有任务中挑选一个适合自己的任务
6.如果当前节点或者当前节点所在的机架上有任务,则获取一个
7.如果当前节点或者当前节点所在的机架上没有可获取的任务,则从其它机架上获取任务
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2013-6-28 10:41:30 |
2013-6-28 10:41:30 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}