大家都熟悉HTTPSession是基于无状态HTTP协议的web应用实现状态的主要方法之一. 利用HTTPSession我们就可以把用户的多个请求关联起来, 来实现诸如购物车等应用.
而在集群环境下,默认情况下每个用户的HTTP Session只会在其首次访问的服务器实例上创建. 如果下次用户的请求被分发到另外的服务器上则是无法获得先前创建的Session. 所以这种情况下我们可以使用HTTPSession Replication在整个集群内共享HTTP Session, 同时也实现高可用性和冗错等特性.
在Weblogic中,HttpSession Replication的方式是通过在weblogic.xml中的session-descriptor的定义persistent-store-type来实现的. persistent-store-type可选的属性包括memory, replicated, replicated_if_clustered, file, jdbc, cookie, async-replicated, async-replicated-if-clustered, async-jdbc, coherence-web.
例如:
[html]view plaincopyprint?
- <weblogic-web-appxmlns="http://xmlns.oracle.com/weblogic/weblogic-web-app"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://xmlns.oracle.com/weblogic/weblogic-web-app http://xmlns.oracle.com/weblogic/weblogic-web-app/1.0/weblogic-web-app.xsd">
- <session-descriptor>
- <persistent-store-type>replicated</persistent-store-type>
- <timeout-secs>60</timeout-secs>
- </session-descriptor>
- </weblogic-web-app>
<weblogic-web-app xmlns="http://xmlns.oracle.com/weblogic/weblogic-web-app" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.oracle.com/weblogic/weblogic-web-app http://xmlns.oracle.com/weblogic/weblogic-web-app/1.0/weblogic-web-app.xsd">
<session-descriptor>
<persistent-store-type>replicated</persistent-store-type>
<timeout-secs>60</timeout-secs>
</session-descriptor>
</weblogic-web-app>
其中persistent-store-type默认为memory, 即不支持replication.
一旦我们的Web应用是部署在集群环境中需要Session Replication时必须选择其他方式, 注意其中file, jdbc,async-jdbc, coherence-web是需要对应的文件,数据库,Coherence等资源必须在Cluster中访问才可能支持replication,所以需要进一步去配置这些资源属性. 而replicated, replicated_if_clustered,async-replicated, async-replicated-if-clustered相当memory模式的cluster版本,没有额外的配置工作,自动在集群内实现Http Session内存主从复制. HTTP Session会自动从用户第一次访问的Weblogic服务器实例复制到另外一个服务器实例的内存中,并保持同步.
但内存复制方式虽然配置简单但也有几个地方需要注意! !
- Load Blanace和Session Affinity问题.
由于这里的机制是主从备份, 所以集群中只有两个实例会有同一HTTP Session的数据. 当集群里的实例多于2个以上时,为了确保后续的HTTP请求能访问到Session数据, 必须要求前置分发请求的load balancer支持session affinity(sticky session/seamless session). Session Affinity就是能够把特定Session的所有请求都路由到第一次创建Session的同一物理机器上;否则后续的请求就有可能不能够访问Session数据了.
如果设置成非Replication方式即memory模式, 生成的JSESSIONID类似:1VBHTlYR0VVjb0L7MMTlZPVXLpQHDCCT17L9yw1qP0T1465w9JXG!1694365319
一旦配置成Replicated模式,Weblogic会生成如下格式的SessionID: sessionid!primary_server_id!secondary_server_id(每个应用服务服务器产生的格式不一定一样, 例如Tomcat使用.分割)
例子: 1bQmTlbQcxfZCTd8pJVvCnJlL23p3JMvGnmFnTJxV3PKBx7nKvwr!1694365319!-1897025151
其中1694365319和-1897025151分别是集群两台主机的server_id.
这时前置的Loader Balancer需要能从Cookie或URL Rewriting中读取和解析这个SessionID, 利用其中server_id和实际的机器地址做映射,实现将某Session的后续请求都发到之前创建HTTP Session的服务器实例上或者备份的实例上. 这里具体的配置就要参考实际相关Loader Balancer的手册了. 现在一般常见的Load Balancer硬件都支持这个功能. 如果是测试, 我们也可以使用软Load Balancer. 例如Apache的MOD_PROXY, 还可以直接使用Weblogic的Proxy Plugin也可以完成同样的功能.
此外如果我们想要控制Session具体复制到集群中指定的某台服务器实例时, 例如考虑到异地冗灾. 我们可以通过配置Replication Groups把不同地方的机器分成不同的组, 这样Weblogic会首先尝试把Session复制到其他组的机器中.
内存复制还有一个常见问题就是内存占用,我们必须控制好http session的大小和生存时间. 否则在高负载下, 即使是最简单的Session对象也会很快把内存消耗掉.
下面是几种模式的性能比较.
测试客户端: Jmeter
线程数: 5
操作系统: Red Hat Enterprise Linux Server release 5.1 (Tikanga)
Welgoic: 10.3.3.0
CPU: Intel(R) Xeon(TM) CPU 3.00GHz
| persistent-store-type | TPS | CPU |
|---|
| 没有session | 9000 | 30% |
| memory | 7000 | 30% |
| replicated | 2100 | 35% |
| async-replicated | 4700 | 30% |
| cookie | 7600 | 30% |
| file | 180 | 8% |
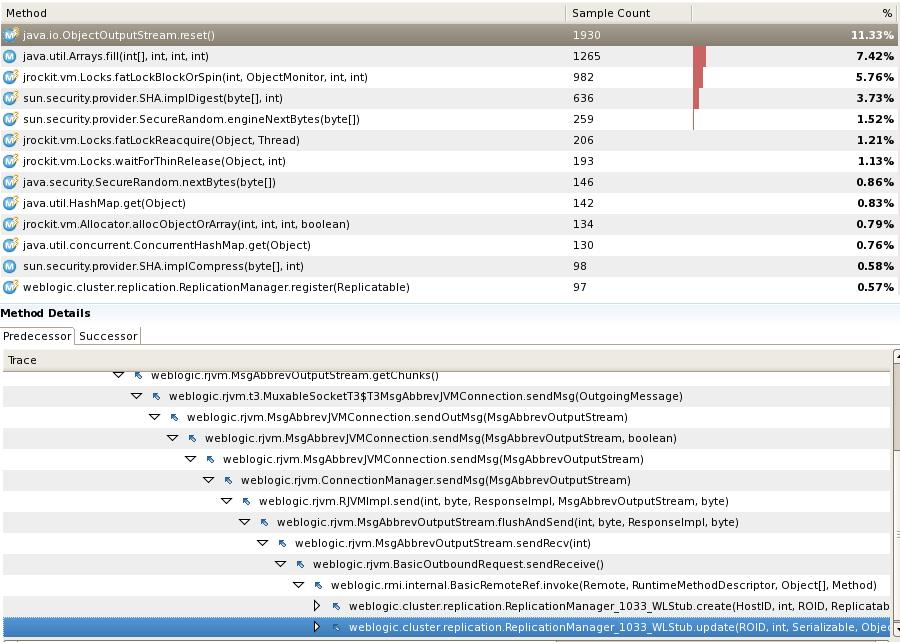
可以看到即使使用异步模式,Session Replicaiton和其它模式(除了文件)相比性能还是有很大差距.
如果跟踪可以看到部分CPU都用在了服务器之间复制Session上.
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2013-3-11 13:56:22 |
2013-3-11 13:56:22 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}