本文转自github,由网友翻译
近期,深度学习在CV界取得了巨大的突破,着实让人兴奋。
但是,关于它们仍然存在一些问题。首先就是神经网络究竟学习了什么,这个很难去理解。即使它训练出高精度的结果来,但是我们还是很难理解它为什么可以成功。如果网络失败了,也很难解释它为什么错了。
虽然深度神经网络如何解释这么难,但是对于低维度的神经网络(每一层只有几个神经元)还是比较简单去解释的。事实上,我们可以通过可视化来了解这类的神经网络训练的过程。这种 会允许我们神经网络和网络节点有更深的直觉拓扑感受。
一个简单的例子
我们先从几个简单的数据集开始,观察图上两个曲线。通过这两组曲线坐标和对应的标签,神经网络将要学习对其他点如何分类。




可视化最简单的方式是看一下每个点进去都发生了什么。
我们从只有一个输入层和一个输出层神经网络开始。用这个神经网络拟合一条曲线来对两类数据进行分类。

这个神经网络的分类不是很如意。现在的神经网络通常不知有两个层,它们在输入层和输出层之间还可能有隐藏层。最少的情况下,它们也有一个隐藏层。
像之前一样,我们可以可视化这个网络的行为,观察其对不同的点的反应。它拟合了比一条直线复杂的曲线分离了数据。

神经网络的每一层都相当于对数据进行了坐标变换,使其变成了另一种表示方式。2我们可以通过分别观察数据在每层的表示方式,来看看神经网络如何对它们进行分类。当我们观察最后一层时,网络会在数据间拟合一条曲线(如果是多维的话,会拟合一个超平面)。
之前的可视化中,我们已经看到了数据的“原始”表示方式。你可以把它想象成输出层。现在我们观察一下,通过第一次转化候,输入变成了什么样子。这其实就是在观察隐藏层。
一个维度对应一个神经元。

可见隐藏层对数据进行了空间变换,使数据变成了线性可分。(隐藏层是两个神经元,所以变换出来并没有升维)
继续对神经网络层进行可视化
前面几节中,我们学到了如何通过观察每个层表示来解释神经网络。这回给我们展示一系列的数据表示方式
棘手的部分是理解如何更进一步的通用的解释 ,值得庆幸的是,神经网络的叠加的属性让通用的解释不是很难。
神经网络中有更重各样的层。我们可以先讲一下tanh层。一个激活函数为tanh的层(Wx+b)包括:
1. 通过权值矩阵W进行线性变换
2. 加上b向量的偏置
3. 逐点进行tanh变换。
我们可以将这些合成连续的变换,如图:
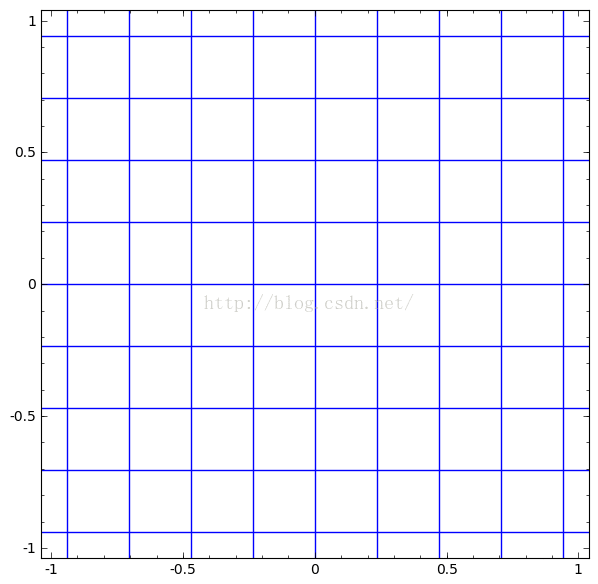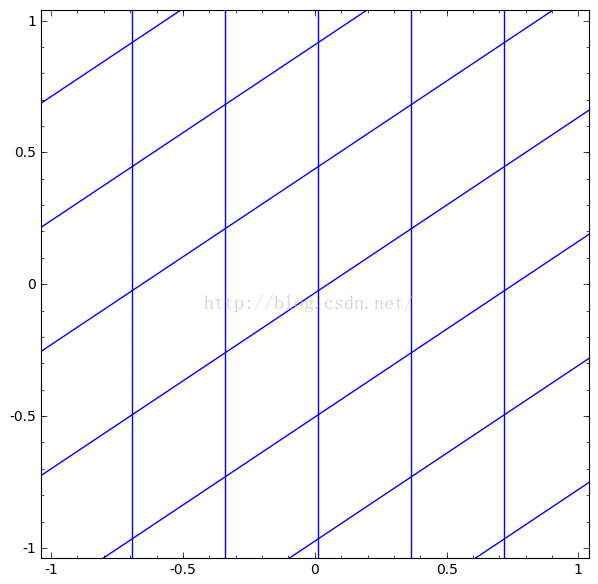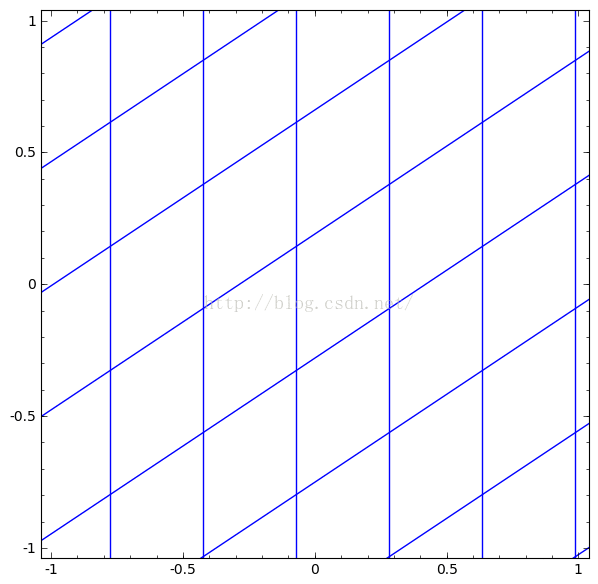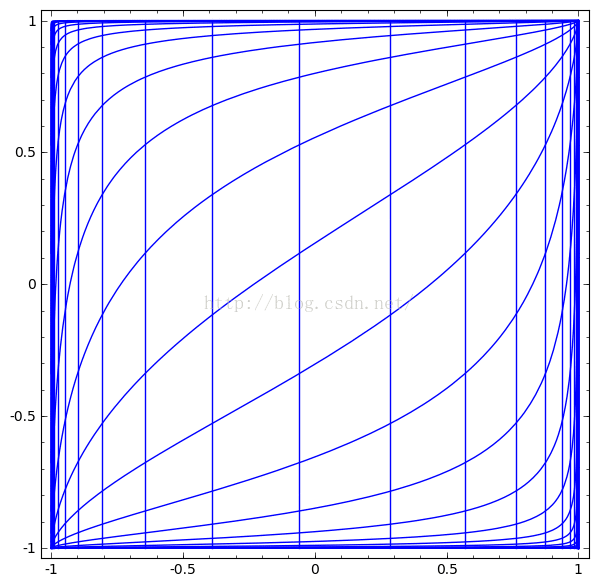
我们可以用这个思想来解释更复杂的网络。例如,下图使用了4个隐藏层的神经网络成功的分别了两个轻微缠绕螺旋线。我们可以看到随着时间变化,在训练的过程原始的数据被映射到高维空间,然后就可以被鉴别了。即便这两个螺旋线刚开始是纠缠在一起的,神经网络最后已可以使其变换成线性可分。
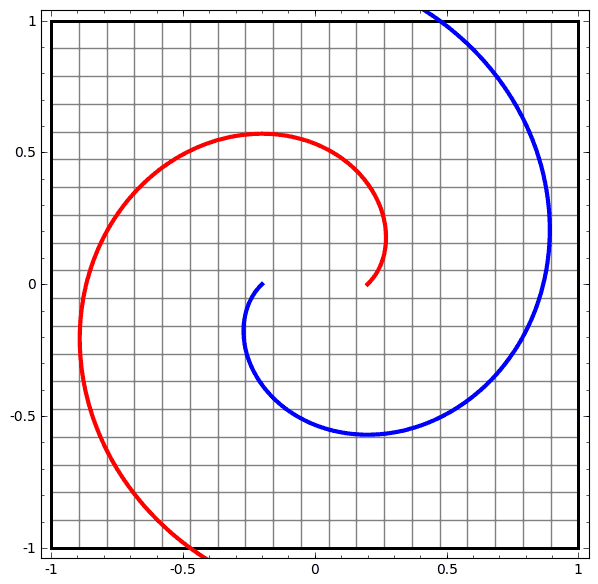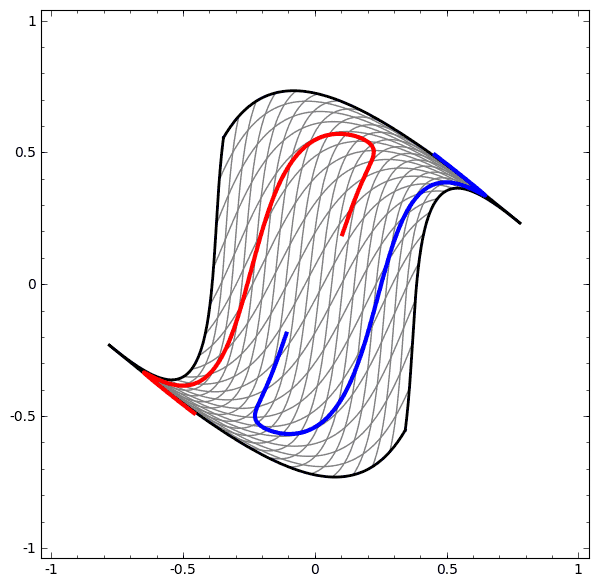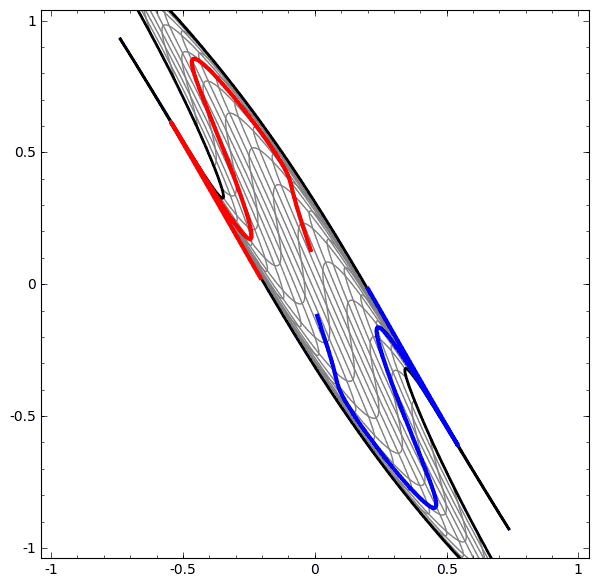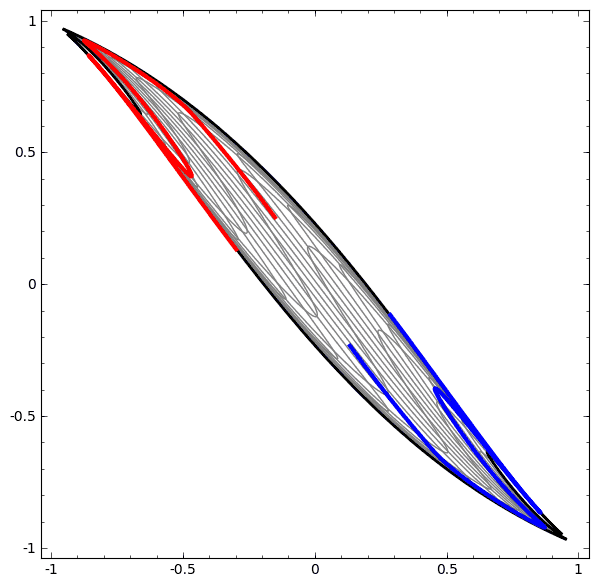
另一方面,下面的螺旋线缠绕的更复杂一些,神经网络已经不能将其成功分类了。
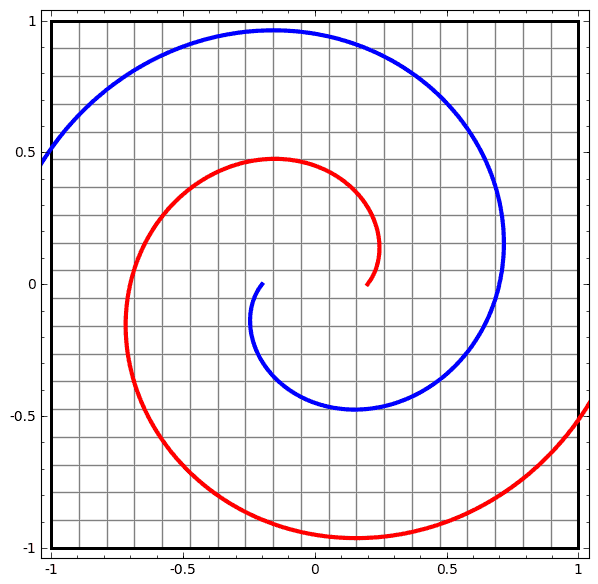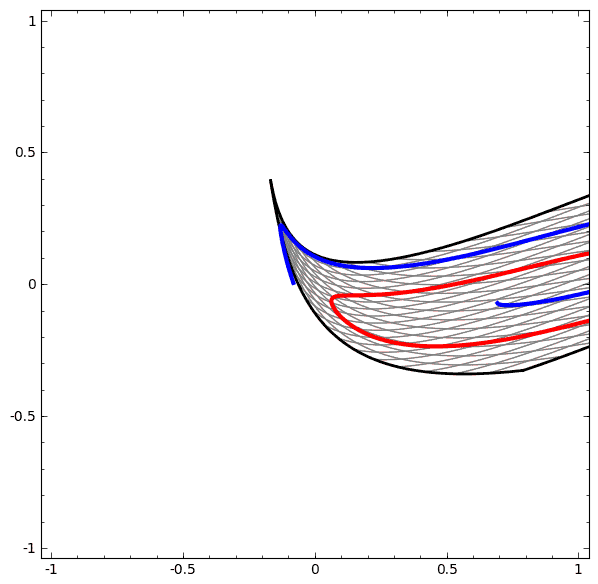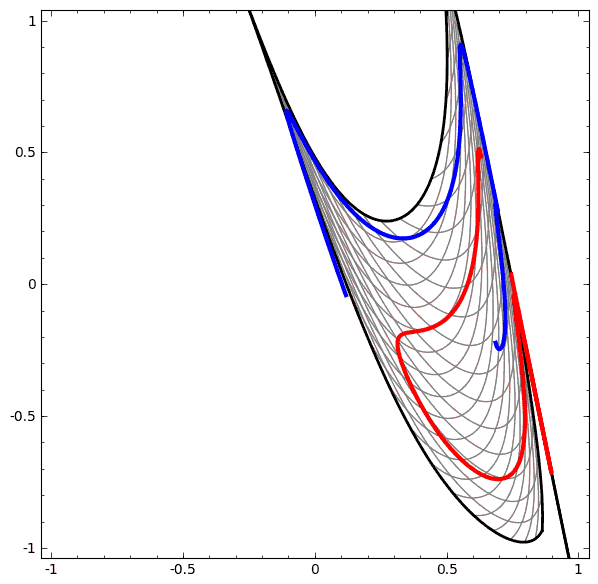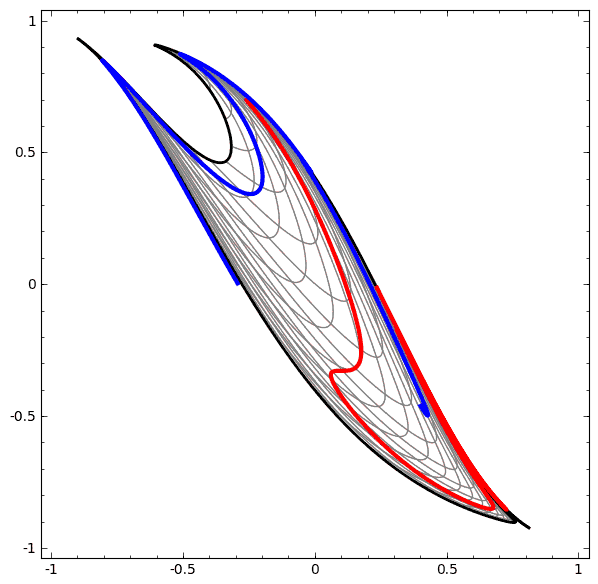
值得一说的是,由于我们使用维度较低的神经网络,实现上面的分类任务会有一点难。如果我们使用节点更多的神经完了过,上面的那些任务就很容易了。
tanh层的拓扑学
每个层都可以对空间进行压缩和伸展,但是它并不能切割,截断或者折叠空间。直觉上,我们可以看到它会保持其拓扑特性。
这些不该拓扑特性的变化被叫做同胚。数学上称它们互为为连续函数的双射。
定理:如果权值矩阵W没有奇点,拥有N层输入和N层输出的神经网络层表示的空间是同胚的。
证明:一步一步的来:
1. 我们假设W矩阵(其行列式非0).
这是一个双射先行函数且是连续的.所以,乘上W是同胚的
2. 变换是同胚的
3. tanh(或者sigmoid,softplus不包括ReU)激活函数是连续的而且它们的逆运算也是连续函数。如果定义域不越界的话,他们是双射变换。每个节点乘以节点也是同胚的。
因此,如果W的行列式不为0的话,这个神经网络层就是同胚的,无论叠加多少这样的层,结果也会是同胚的。
拓扑和分类

A类为红色,B类是蓝色。它们是两个二维的数据集, A,B⊂R2:
A={x|d(x,0)<1/3}
B={x|2/3<d(x,0)><1}
声明:如果神经网络中的隐藏层中没有一个节点数超过3,那么无论它有多深也没有拌饭对以上的数据进行分类.
就像上面提到的,利用sigmoid或者softmax单元对A,B进行分类就等于在神经网络的最后一层表示中找到一个超平面来分离A和B。通过仅仅两个隐藏层节点,是没有能力分开这些数据的。
在下图的可视化中,我们观察训练过程中数据在神经元隐藏层的表示和拟合出来的分界线。我们可以看到他正在挣扎着去学习。

最后它终于挣扎着找到了局部最优点,但并没有完全的线性可分。不过,它的正确率约为80%,还可以吧。即使这个例子中有很多这样的隐藏层,也是不会成功的。
证明:如果权值W的行列式不为0的话,每个层都是同胚的。这样的情况下,
A,始终是被B包围的, 分割线并不不能正确的分类。如果W的行列式为0,那么数据集就会塌缩到一维的坐标中去。这样的情况下塌缩到一个坐标中区,数据A和数据B就会混合这样就更不可能成功分类了。
如果我们在隐藏层中,加入第三个神经元,问题就迎刃而解了。 神经网络学出了下图的表示方式:

有了这种表示方式,我们就可以用一个超平面对数据进行分类了。
为了更好的理解到底发生了什么,我们先考虑一个更简单的一维的数据:

A=[ -13,13](线段)
B=[−1,−23]∪[23,1]
如果神经网络的神经元不超过两个的化,我们不能这个数据集进行分类。但隐藏层含有两个神经元时,神经网络便可以拟合出一条漂亮的分类曲线了。

流形假设
这些和真实的数据一样吗,比如说图片之类的?这就要涉及到流形假设了。
流形假设即某些高维数据,实际是一种低维的流形结构嵌入在高维空间中这个假设已经有理论和实验上的支持。如果你相信这条假设,这么机器学习分类问题本质上是对一串纠缠在一起的流形进行分离。
之前的例子中,一个类别的数据被另一个类别的数据“包围”起来了。但是,这并不能说明一只狗的流形会把猫的流形完全包围起来。但是,这里还会存在另一种更复杂的拓扑结构。
链环和同伦
另一个有趣的数据集是两个链环:A和B。

像之前的数据集一样,但这个数据集无法用n+1维的变换使其变得线性可分。
(也就是4维)
th dimension.
链环是在绳结理论一个概念,也是拓扑学领域的知识。有时候我们看到一个链环,并不能立即确定是否可以把它解开。

一个相对可以解开的链环
如果一个隐藏层包含3个神经元的神经网路可以对其进行分类,说明它是可以解开的链环。(问题:所有的可解链环都可以用含有三个神经元的神经网络解开吗?)
根据绳结理论的观点,神经网络隐层带来的数据方式变换过程就是解绳结的过程。在拓扑学中,两个绳结形态如果可以通过有限次变换得到就说它们是同痕的。
定理: 神经网络输入输出对应空间是同痕的,前提是W没有奇点
证明: Again, we consider each stage of the network individually:
1. The hardest part is the linear transformation. In order for this to be possible, we need W to have a positive determinant. Our premise is that it isn’t zero, and we can flip the sign if it is negative by switching two of the hidden neurons, and so we can guarantee the determinant is positive. The space of positive determinant matrices is path-connected, so there exists p:[0,1]→GLn(R) 5 such that p(0)=Id and p(1)=W . We can continually transition from the identity function to the W transformation with the function x→p(t)x , multiplying x at each point in time t by the continuously ransitioning matrix p(t)
2. We can continually transition from the identity function to the b translation with the function x→x+tb
3. We can continually transition from the identity function to the pointwise use of σ with the function: x→(1−t)x+tσ(x)
I imagine there is probably interest in programs automatically discovering such ambient isotopies and automatically proving the equivalence of certain links, or that certain links are separable. It would be interesting to know if neural networks can beat whatever the state of the art is there.
(Apparently determining if knots are trivial is NP. This doesn’t bode well for neural networks.)
上述讨论的锁环数据似乎在真实世界中是不存在的,但如果维度更高,貌似这些数据在真实世界中是存在的。
锁环和绳结如果是1维的流形,那我们需要4维的神经元去解开它,如果更高的维度的话那么需要更多的神经元去解开它,对应的公式是n和2n+2。
避重就轻
神经网络对待这种问题,用了很简单的路线:尽力去把分离的流形拉长,并可能使缠在一起部分变得细小。虽然这不是天才的解决方案,但是它也可以获得相对很高的正确率。

It would present itself as very high derivatives on the regions it is trying to stretch, and sharp near-discontinuities. We know these things happen.7 Contractive penalties, penalizing the derivatives of the layers at data points, are the natural way to fight this.Since these sort of local minima are absolutely useless from the perspective of trying to solve topological problems, topological problems may provide a nice motivation to explore fighting these issues.
换一个角度来讲,如果我们只关心分类的正确率,其实上面的分类方法就足够了。
操作流形更好的神经网络层?
进一步我想其实标准的神经网络就是通过仿射变换和激活函数,没有别的了。很难说这是最好的方式来操作流形
可能我们需要不同种类的网络层和传统的层来混合。
我自然而然想到的是训练出一个向量场,来移动原来的数据。

这是变换后的空间。

One could learn the vector field at fixed points (just take some fixed points from the training set to use as anchors) and interpolate in some manner.上面的向量场可以表示为
F(x)=v0f0(x)+v1f1(x)1+f0(x)+f1(x)
Where v0
and v1
are vectors and f0(x)
and f1(x)
are n-dimensional gaussians.这是有径向基函数启发得到的。
k近邻层
我开始想,线性分类或许不应该是神经网络最合理的需求。某种情况下,K-nn分类应该是最合理的要求。但是K-nn成功的前提是,它要分类的数据表示的很好。所以使用knn之前,事先应该让数据有合理的分布。
首先,我训练了识别MNIST手写数据的卷积神经网络(两个卷积层,没有dropout层),得到的测试错误率为1%。
test error.然后我去掉了softmax层使用k-NN分类,测试错误率降为了0.1-0.2%。
同样,这感觉并不正常。神经网络仍在尽力的使数据线性可分,但由于我们最后使用的是knn分类,原来因线性分类导致的错误变小了。
k-NN is differentiable with respect to the representation it’s acting on, because of the 1/distance weighting.这样,我们可以训练一个神经网络最后做knn分类。这可以被认为是区别与softmax层的“最近邻”层。
我们并不想要前向计算这个训练集,因为这样话费的计算代价太大了。 I think a nice approach is to classify each element of the mini-batch based on the classes of other elements of the mini-batch, giving each one a weight of 1/(distance from classification target).9
不幸的是,使用较复杂的结构,K-nn测试错误率达到了5-4%,更别提简单的结构了。不过,我并没有怎么调参数。
不过,我仍然看好这种方式,因为这样神经网络工作的更合理一些。 We want points of the same manifold to be closer than points of others, as opposed to the manifolds being separable by a hyperplane. This should correspond to inflating the space between manifolds for different categories and contracting the individual manifolds.这样就感觉简单一点了。
结论
低维度的神经网络无论有多少层也不能使一些类络链环状的数据集线性可分甚至在一些理论可实现的螺旋结构中,低维的神经网络鉴别也会碰到困难。
为了精确给这些数据进行分类,更宽的神经网络是必须的。进一步讲,传统的神经网络在进行这流形操作时并不是特别好。即使我们手工设置参数,但是要完全模拟出我们想要的流形变换来也是比较困难的。新的神经网络层,尤其是更切近流形变换概念的层,或许应该被补充进来。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2018-8-31 16:14:34 |
2018-8-31 16:14:34 |

 赞(
赞( 操作
操作
{kind=link}
{kind=link}