在MySQL中最常见的乱码问题的起因就是把错进错出神话。所谓的错进错出就是,客户端(web或shell)的字符编码和最终表的字符编码格式不同,但是只要保证存和取两次的字符集编码一致就仍然能够获得没有乱码的输出的这种现象。但是,错进错出并不是对于任意两种字符集编码的组合都是有效的。我们假设客户端的编码是C,MySQL表的字符集编码是S。那么为了能够错进错出,需要满足以下两个条件
MySQL接收请求时,从C编码后的二进制流在被S解码时能够无损
MySQL返回数据是,从S编码后的二进制流在被C解码时能够无损
编码无损转换
那么什么是有损转换,什么是无损转换呢?假设我们要把用编码A表示的字符X,转化为编码B的表示形式,而编码B的字形集中并没有X这个字符,那么此时我们就称这个转换是有损的。那么,为什么会出现两个编码所能表示字符集合的差异呢?如果大家看过博主之前的那篇 十分钟搞清字符集和字符编码,或者对字符编码有基础理解的话,就应该知道每个字符集所支持的字符数量是有限的,并且各个字符集涵盖的文字之间存在差异。UTF8和GBK所能表示的字符数量范围如下
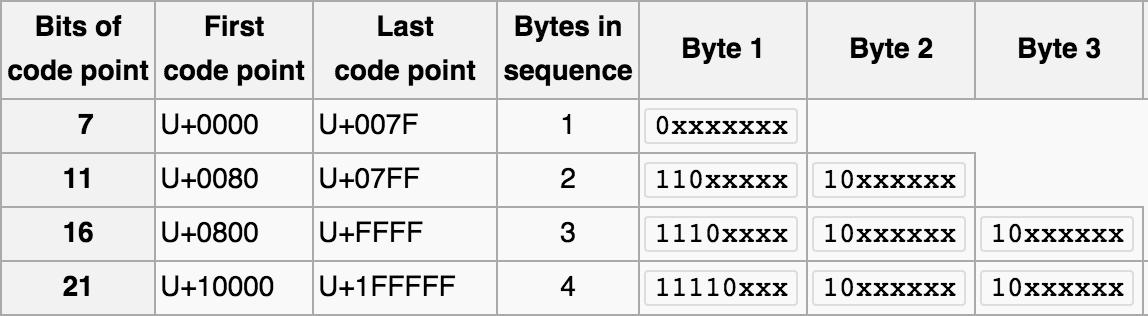
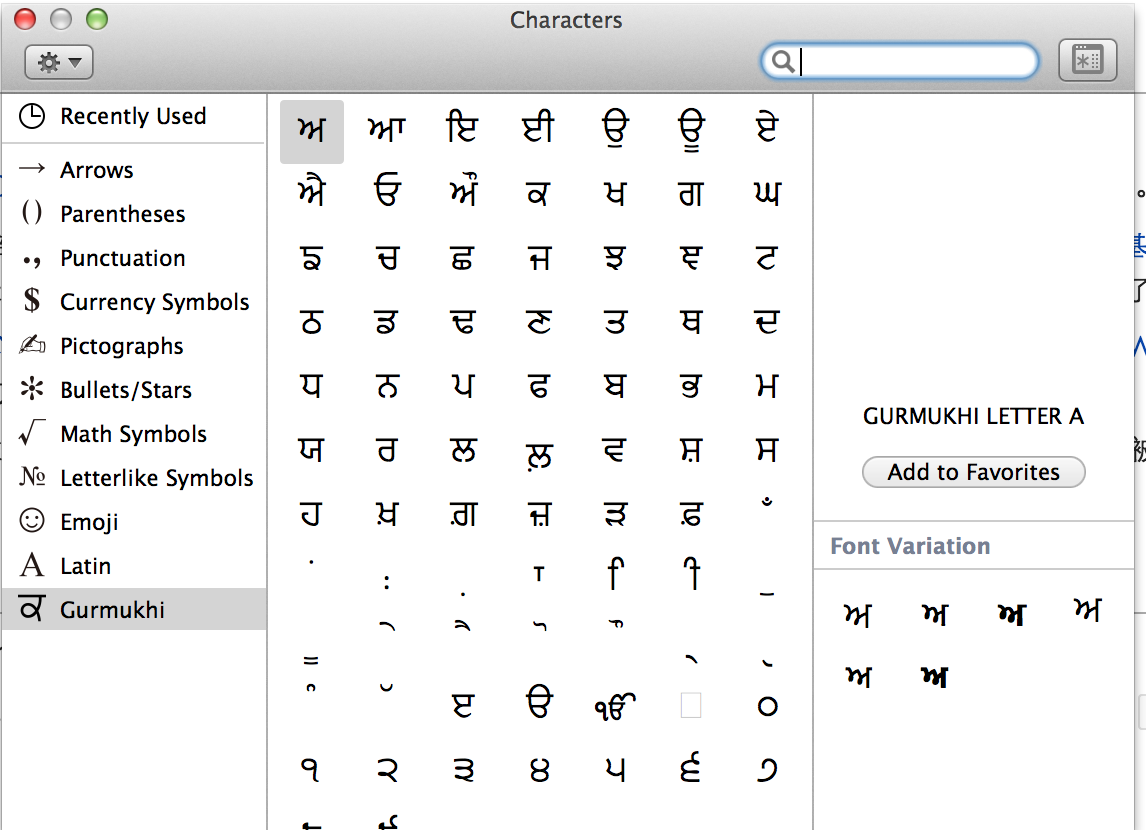
由于UTF-8编码能表示的字符数量远超GBK。那么我们很容易就能找到一个从UTF8到GBK的有损编码转换。我们用字符映射器(见下图)找出了一个明显就不在GBK编码表中的字符,尝试存入到GBK编码的表中。并再次取出查看有损转换的行为
字符信息具体是:ਅ GURMUKHI LETTER A Unicode: U+0A05, UTF-8: E0 A8 85
在MySQL中存储的具体情况如下:

出错的部分是在编解码的第3步时发生的。具体见下图
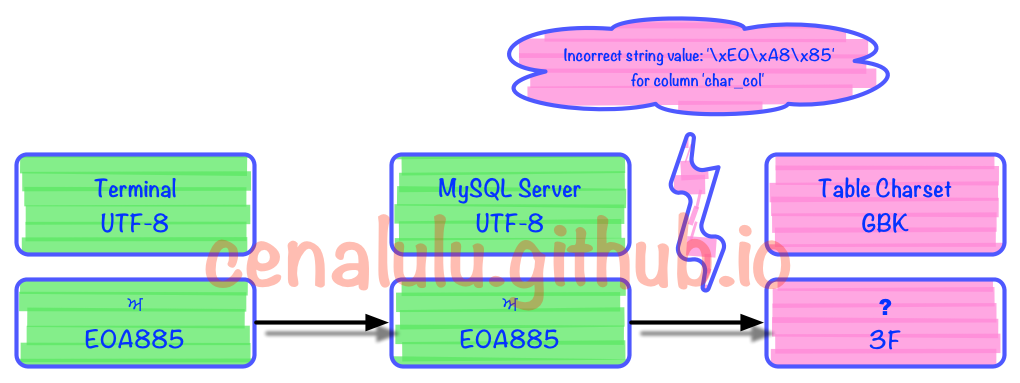
可见MySQL内部如果无法找到一个UTF8字符所对应的GBK字符时,就会转换成一个错误mark(这里是问号)。而每个字符集在程序实现的时候内部都约定了当出现这种情况时的行为和转换规则。例如:UTF8中无法找到对应字符时,如果不抛错那么就将该字符替换成� (U+FFFD)
那么是不是任何两种字符集编码之间的转换都是有损的呢?并非这样,转换是否有损取决于以下几点:
关于第一点,刚才已经通过实验来解释过了。这里来解释下造成有损转换的第二个因素。从刚才的例子我们可以看到由于GBK在处理自己无法表示的字符时的行为是:用错误标识替代,即0x3F。而有些字符集(例如latin1)在遇到自己无法表示的字符时,会保留原字符集的编码数据,并跳过忽略该字符进而处理后面的数据。如果目标字符集具有这样的特性,那么就能够实现这节最开始提到的错进错出的效果。
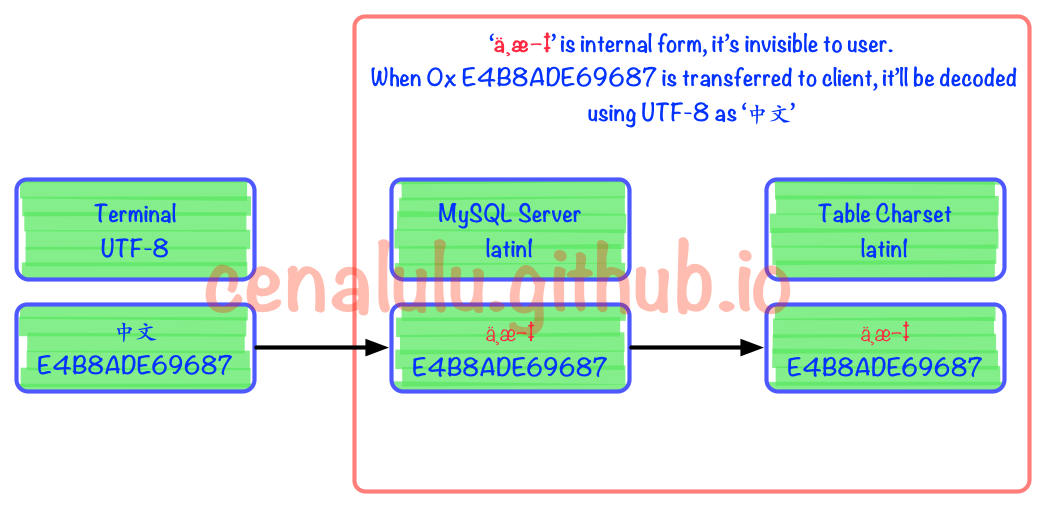
我们来看下面这个例子

具体流程图如下。可见在被MySQL Server接收到以后实际上已经发生了编码不一致的情况。但是由于Latin1字符集对于自己表述范围外的字符不会做任何处理,而是保留原值。这样的行为也使得错进错出成为了可能。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-8-27 9:41:07 |
2015-8-27 9:41:07 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}