正则表达式使用单个字符串来描述、匹配一系列符 合某个句法规则的字符串,即由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索 的字符串进行匹配。
一、元字符
1.1 […] 字符组(Character Classes)
字符组可以匹配[ ]中包含的任意一个字符。虽然可以是任意一个,但只能是一个。
字符组支持由连字符“-”来表示一个范围。当“-”前后构成范围时,要求前面字符的码位小于后面字符的码位。
[^…] 排除型字符组。排除型字符组表示任意一个未列出的字符,同样只能是一个。排除型字符组同样支持由连字符“-”来表示一个范围。
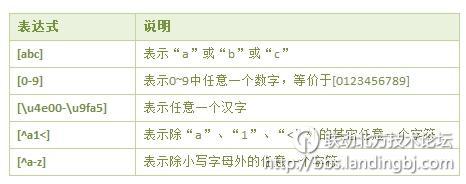
举例:
“[0-9][0-9]”在匹配“Windows 2003”时,匹配成功,匹配的结果为“20”。
“[^inW]”在匹配“Windows 2003”时,匹配成功,匹配的结果为“d”。
1.2 常见字符范围缩写
对于一些常用的字符范围,如数字等,由于非常常用,即使使用[0-9]这样的字符组仍显得麻烦,所以定义了一些元字符,来表示常见的字符范围。

举例:
“\w\s\d”在匹配“Windows 2003”时,匹配成功,匹配的结果为“s 2”。
1.3 . 小数点
小数点可以匹配除“\n”以外的任意一个字符。如果要匹配包括“\n”在内的所有字符,一般用[\s\S],或者是用“.”加(?s)匹配模式来实现。

1.4 其它元字符

举例:
“^a”在匹配“cba”时,匹配失败,因为表达式要求开始位置后面是字符“a”,而“cba”显然是不满足的。
“\d$”在匹配“123”时,匹配成功,匹配结果为“3”,这个表达式要求匹配结尾处的数字,如果结尾处不是数字,如“123abc”,则是匹配失败的。
1.5 转义字符
一些不可见字符,或是在正则中具有特殊意义的元字符,如想匹配字符本身,需要用“\”对其进行转义。

以下字符在匹配其本身时,通常需要进行转义。在实际应用中,根据具体情况,需要转义的字符可能不止如下所列字符
. $ ^ { [ ( ) * + ? \
1.6 量词(Quantifier)
量词表示一个子表达式可以匹配的次数。量词可以用来修饰一个字符、字符组,或是用()括起来的子表达式。一些常用的量词被定义成独立的元字符。

注意:在不是动态生成的正则表达式中,不要出现“{1}”这样的量词,如“\w{1}”在结果上等价于“\w”,但是会降低匹配效率和可读性,属于画蛇添足的做法。
1.7 分支结构(Alternation)
当一个字符串的某一子串具有多种可能时,采用分支结构来匹配,“ ”表示多个子表达式之间“或”的关系,“ ”是以()限定范围的,如果在“ ”的左右两侧没有()来限定范围,那么它的作用范围即为“ ”左右两侧整体。

举例:
“^aa b$”在匹配“cccb”时,是可以匹配成功的,匹配的结果是“b”,因为这个表达式表示匹配“^aa”或“b$”,而“b$”在匹配“cccb ”时是可以匹配成功的。
“^(aa b)$”在区配“cccb”时,是匹配失败的,因为这个表达式表示在“开始”和“结束”位置之间只能是“aa”或“b”,而“cccb”显然是不满足的。
二、Java中正则表达式的使用
指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建 Matcher 对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式。
因此,典型的调用顺序是
Pattern p = Pattern.compile("a*b"); Matcher m = p.matcher("aaaaab"); boolean b = m.matches();
在仅使用一次正则表达式时,可以方便地通过此类定义 matches 方法。此方法编译表达式并在单个调用中将输入序列与其匹配。语句
boolean b = Pattern.matches("a*b", "aaaaab");
例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test
{
public static void main(String[] args)
{
//定义一个正则表达式,匹配任意个a和2~5个b组成的字符串
String regex = "a*b{2,5}";
//编译表达式
Pattern p = Pattern.compile(regex);
String str ="aaaaabb";
Matcher m = p.matcher(str);
boolean b = m.matches();
System.out.println(b); //输出:true
//reset()方法,可将现有的Matcher对象应用于一个新的字符序列。
str ="aaaaaadsddsdbb";
m.reset(str);
System.out.println(m.matches()); //输出:false
str ="bbbb";
m.reset(str);
System.out.println(m.matches()); //输出:true
str = "aaaaaahellobbbbbaabbabbbworldab@@&*goodabbbbbbbbbb";
m.reset(str);
//查找所有匹配模式的字符串,并打印出来
//输出:bbbbb,aabb,abbb,abbbbb,bbbbb,
while(m.find())
{
System.out.print(m.group()+",");
}
System.out.println();
//用,替换所有匹配模式的字符串
//输出:aaaaaahello,,,worldab@@&*good,,
String str1 = str.replaceAll(regex, ",");
System.out.println(str1);
//将字符串以用匹配模式的字符串为界来划分数组
//输出:aaaaaahello,,,worldab@@&*good,
String[] arrays = str.split(regex);
System.out.println(arrays.length); //4
for(String s:arrays)
{
System.out.print(s+",");
}
System.out.println();
}
}
三、贪婪与懒惰模式
Ø 从语法角度看贪婪与懒惰
被匹配优先量词修饰的子表达式,使用的是贪婪模式;被忽略优先量词修饰的子表达式,使用的是懒惰模式。它们的区别在于重复限定修饰符的后面是否有问号,有的话就是懒惰模式,否则就是贪婪模式。
匹配优先量词包括:“{m,n}”、“{m,}”、“?”、“*”和“+”。
忽略优先量词包括:“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
Ø 从应用角度看贪婪与懒惰
贪婪与懒惰模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配;而懒惰模式在整个表达式匹配成功的前提下,尽可能少的匹配。懒惰模式只被部分NFA引擎所支持。
Ø 从匹配原理角度看贪婪与懒惰
能达到同样匹配结果的贪婪与懒惰模式,通常是贪婪模式的匹配效率较高。
所有的懒惰模式,都可以通过修改量词修饰的子表达式,转换为贪婪模式。
贪婪模式可以与固化分组结合,提升匹配效率,而懒惰模式却不可以。
例:
源字符串:aa<div>test1</div>bb<div>test2</div>cc
正则表达式一:<div>.*</div>
匹配结果一:<div>test1</div>bb<div>test2</div>
正则表达式二:<div>.*?</div>
匹配结果二:<div>test1</div>
四、常用正则表达式
1、匹配中文字符的正则表达式: [\u4e00-\u9fa5]
2、匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
3、匹配首尾空白字符的正则表达式:^\s* \s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
4、匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
5、匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
6、匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
7、匹配国内电话号码:\d{3}-\d{8} \d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
8、匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
9、匹配身份证:\d{15} \d{18}
评注:中国的身份证为15位或18位
10、匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
 发起投票
发起投票

 技术讨论
技术讨论






 加好友
加好友 发消息
发消息 2015-4-8 15:03:23 |
2015-4-8 15:03:23 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}